


Xbotics 具身智能学习路线(Xbotics Roadmap to Embodied-AI)
Xbotics 社区具身智能学习指南:我们把“具身综述→学习路线→仿真学习→开源实物→人物访谈→公司图谱”串起来,帮助新手和实战者快速定位路径、落地项目与参与开源。


面向“机器人基础学习 + 开源项目学习”,强调可复现与快速上手;不追求百科全书,而是清晰路径 + 工程落地。
使用说明
定位:面向新人、进阶与工程落地;以“路线+清单+实作任务”组织,而非长篇教程。
风格:中文为主、英文补充;强调开源项目与可复现。
先修建议:Python / 线性代数 / 概率统计 / 控制基础 / Linux & Git。
图标约定:⭐ 必看 · 🧪 实作 · 🧱 SOP · 📦 代码/数据 · 📄 论文 · 🎥 视频(可选)。
结构:每个小节优先给出可操作的“起步三件事”。
更偏重机器人基础学习与开源项目实践 · 非“教程”,而是可以执行的学习路线与资源导航
—————————————————————————————————————————————————————————————————————————————————————————
贡献者
@Xbotics-木木、@Xbotics-土豆、@FTZP、@KandS、@maomao725
🎯 想加入?见文末「如何贡献」。
—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
目录
1. 具身综述(Embodied AI Overview)
贡献者:@owner,@alice
你将获得:统一术语、问题划分与评测框架;从“感知—决策—控制—评测”建立大图景。
目录(Table of Contents)
—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
1.1.1 学习范式与策略框架(IL / RL / VLA / Diffusion Policy / World Model)
行为克隆(Behavior Cloning, BC):把控制当成监督学习:输入观测/指令,输出动作。优点是数据友好、上手快;缺点是分布外脆弱(covariate shift),需靠干预/DAgger/重置策略兜底。
逆强化学习(Inverse Reinforcement Learning, IRL)/偏好学习:先学“奖励/偏好”,再用 RL 求策略;泛化好,但链路长、训练贵。
GAIL / 对抗模仿:通过判别器让“机器人轨迹像专家”,绕开显式奖励建模。对抗稳定性与探索机理是工程挑战。
离线 RL / 在线 RL / Offline-to-Online(O2O):离线:全靠静态数据、安全可控;在线:探索充分但要解决安全与成本;O2O:先离线“站起来”,再在线“走起来”,符合工程常识。
层级策略(Hierarchical Policy):高层做子目标/技能编排(options / behavior trees / task graphs),中层学习原子技能,低层用跟踪控制/安全壳执行。
VLA(视觉–语言–动作, Vision–Language–Action):从视觉–语言模型(VLM)微调到端到端控制:看图、听指令、输出动作,同步提升开放词汇与长时序任务能力。
扩散策略(Diffusion Policy):用生成模型在轨迹/动作分布上采样,天然平滑、抗噪,易接视觉/语言条件;部署时注意采样延迟与实时间隔对齐。
世界模型(World Model, WM):学习“可微的环境动态”,在潜空间里做规划/MPC/RL,把昂贵的真机交互换成“脑内演练”;关键在表征学习、模型偏差控制、闭环落地。
残差学习与模型融合:用 MPC/几何控制做“主干”,RL/IL 学残差/补偿(摩擦、柔顺、延迟、未建模动力学),在工业里很常见。
安全壳(Safety Shield):策略外层的速度/力矩限幅、碰撞守卫、紧急制动与可达性过滤,用于上线阶段风险控制与可解释合规。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.2 控制与规划常用概念
PID 控制:比例-积分-微分反馈控制,调参直观但对时延/强耦合系统需小心。
计算力矩 / 反馈线性化(Computed-Torque Control):用模型抵消非线性,等效成线性目标再配 PD/PI。
阻抗/导纳控制(Impedance / Admittance Control):在末端力–位移间设“机械阻抗”,适合接触/打磨/装配任务。
MPC(模型预测控制):滚动优化、显式处理约束;实时性依赖求解器与模型精度。
规划方法:样条插补(轻量)、PRM/RRT(高维可行性)、TrajOpt/CHOMP/STOMP(平滑高质)。
任务–技能–执行分层:语言/图搜索/LLM 负责任务分解;技能网络(抓、推、开合…)产出子目标;低层控制稳定落地。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.3 感知与表征(Robotics Models)
视觉编码器:ResNet、ViT、DINO 等提取语义与几何;点云侧 PointNet、PointTransformer 做位姿/重建/抓取。
VLM/LLM 融合:CLIP、SigLIP 语义对齐;LLaVA、PaLM-E、Prism 等多模态骨干用于目标描述、子目标定位、失败解释。
表示学习:SE(3) 等变、神经隐式(SDF/NeRF/3DGS)、可供性图(Affordance Map)、接触图谱。
状态估计与多传感融合:RGB-D / IMU / 力矩 / 视觉跟踪,重点是时间同步与标定(手–眼、外参、时延)。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.4 系统工程(Robot System Engineering)
手–眼标定(AX=XB / A=XBY):求相机与机械臂坐标系刚体变换。
URDF / ROS:机器人结构、惯量、关节、碰撞的统一描述格式。
DH 参数与现代几何表示:关节链参数化、雅可比、奇异性分析。
记录与回放(Log & Replay):全链路时间戳、同步、丢包/延迟管理;用于离线评测、回归测试、复现实验。
仿真到实机(Sim2Real):域随机化、参数扰动、传感噪声/延迟注入、重置策略与安全门限一致化。
模型评估(Model Selection):成功率、完成时长、动作频率、回报;多任务场景关注最终阶段一致性,单任务场景关注最佳 checkpoint + 滑动平均。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.5 人机交互(HRI)
共享控制(Shared Autonomy):人提供意图/指令,机器人做低层补偿与安全保障。
可解释性(Explainability / Justification):策略过程可被人理解、可追溯。
信任与接受度(Trust & Acceptance):人对系统可靠性/可控性的主观信任度,影响系统投放与合规。
社交导航(Proxemics):在人群环境中机器人保持合适距离、礼貌行为与交互方式。
Wizard-of-Oz 实验:早期 HRI 数据采集中常用“人类暗中接管机器人行为”来收集真实交互数据。
社区与会议:ACM/IEEE HRI 是人机交互领域旗舰年会;ACM THRI 是相关期刊。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.6 安全与标准
ISO 10218-1 / -2:工业机器人及其系统安全要求(机械、控制、集成)。
ISO/TS 15066:协作机器人(cobot)安全指南(人机共域力限值、协作模式、安全模式等)。
👉 这些标准是落地部署/验收时常被查验的条款,建议据此设计“速度/力矩限幅、停止等级、围栏/扫描仪联锁”等安全壳。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.7 常见文件与工具栈
URDF / SRDF / xACRO:机构学与语义描述格式。
USD / GLB:高保真几何交换格式。
ROS / ROS 2:通信中间件;tf/tf2 用于坐标变换。
MoveIt:常用运动规划&碰撞检测框架。
Isaac Lab / ManiSkill / RoboSuite / RLBench:主流仿真平台/基准套件。
PyTorch / JAX:模型训练栈。ONNX / TensorRT:部署加速栈。
Opt / OSQP / qpOASES:MPC/QP 求解器工具。
Bag / MCAP:日志与回放格式。
—————————————————————————————————————————————————————————————————————————————————————————
1.1.8 行业顶会 / 顶刊
🧭 会议(Conferences)
ICRA – IEEE Intl. Conf. on Robotics and Automation
IROS – IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems
RSS – Robotics: Science and Systems
CoRL – Conference on Robot Learning
Humanoids / CASE / ISRR / ISER 等专题会议
📘 期刊(Journals)
IEEE Transactions on Robotics (T-RO)、IEEE Robotics and Automation Letters (RA-L)
The International Journal of Robotics Research (IJRR)、Autonomous Robots (AURO)
Science Robotics
Journal of Field Robotics (JFR)
ACM THRI(人机交互领域旗舰期刊)
—————————————————————————————————————————————————————————————————————————————————————————
1.1.9 机器人基础(Robotics Basics)
自由度(DoF)/工作空间:构型可动维数与末端可达区域。
正/逆运动学(FK/IK):通过关节角求末端位姿;或反求关节角。雅可比矩阵用于速度/力映射与奇异性分析。
动力学:包含惯量、科氏力、离心力、重力项;控制器设计必须考虑执行器力矩、关节摩擦、负载变化。
外参/内参/时间同步:摄像头、IMU、力传感器等多模态传感器融合基础。
手–眼/基–世界标定(AX = XB / A = XBY 问题):求解机器人末端与相机之间或机器人基座与世界坐标系的变换。
可供性(Affordance):物体“可被如何用”的语义线索,常用于抓取/操作点预测。
可达性/可操作性(Reachability / Manipulability):指给定关节限制/障碍环境下,末端能否达到目标位姿或姿态灵活度。
接触建模/摩擦锥模型:抓取与装配任务中接触力、接触面、摩擦参数的基础物理模型。
软硬件在环(HIL / SIL):在上线前用模拟(软件/硬件)环境验证系统闭环性能与安全。
—————————————————————————————————————————————————————————————————————————————————————————
1.2-操作综述
🤖 机器人操作(Robot Manipulation)综述
一文搞清“从感知到动作”的关键脉络与落地路线:用 数据驱动 的 表示—策略—执行 链路,支撑在 家庭、工业、农业、科学 等真实场景中的泛化与稳定。
目标是“够用、可落地”:不面面俱到,但给到每一条主线的代表性工作与开源落地点。
—————————————————————————————————————————————————————————————————————————————————————————
🧠 为什么是“具身智能中的操作”
本节导读:本节回答“为什么要做操作”。操作是具身智能的闭环中枢:感知 → 表征/理解 → 决策/规划 → 执行/安全。
它与纯感知或语言任务不同,强调物理可行性、实时性与安全性。理解这点有助于选择合适的数据、策略与系统工程路线。
近年进展主要来自三股合力:
大模型与表征:如 R3M、VIP、VC-1 等,让机器人复用通用视觉/多模态编码器。
策略范式创新:Transformer、Diffusion、Flow Matching、SSM 等提升动作建模能力。
数据飞轮机制:从遥操采集 → 合成扩增 → 自动纠错 → 再训练构成循环。
—————————————————————————————————————————————————————————————————————————————————————————
⚙️ 全栈视角:从感知到动作的四层架构
本节导读:这里给出工程上常用的“四层分工”,便于团队分拆与接口定义。
建议把模块边界、消息格式和时序确定清楚,后续替换任意一层(如策略或控制)都更顺滑。
1. 感知与编码(Perception & Encoding)
视觉(RGB/RGB-D/点云)、触觉(高分辨率皮肤/力觉)、音频、IMU/关节状态等。
目标:学得通用、可迁移的语义与几何表征,支撑下游策略。
2. 潜在学习(Latent Learning)
通过对比/自监督/视频-语言/价值隐式等,学到与任务相关的紧凑潜在空间;
“潜在动作”(离散/连续)进一步成为控制接口,连接表示与策略。
3. 策略学习(Policy Learning)
MLP/Transformer 自回归、扩散策略(Diffusion Policy)、流匹配(Flow Matching)、**SSM(Mamba)**等;
关注长时依赖、动作多模态、实时性、等变性(SE(3)/SIM(3))与安全约束。
4. 执行与安全(Control & Safety)
轨迹生成/插补、阻抗/力控、限位/碰撞/急停;
工程上通过**高层(语义/关键姿态)+ 低层(闭环力位控)**提升稳定性与安全性。
—————————————————————————————————————————————————————————————————————————————————————————
🔍 表示学习:可迁移的感知与潜在空间
本节导读:表示是“共用底座”。你需要一个能跨物体、跨场景、跨任务的稳定表征,否则策略在分布外就会崩。
建议先选一个通用视觉编码器(R3M/VIP/VC-1),再视任务引入潜在动作或世界模型。
通用视觉与多模态预训练
R3M:基于 Ego4D 的时间对比视频语言表征。
VIP:基于目标价值的隐式预训练。
VC-1 / Theia / RPT:从人类视频或机器人轨迹学习世界模型式特征。
潜在动作与世界模型
动作/状态离散化为 token 或连续向量,作为策略接口,便于迁移与复用;
视频世界模型预测未来潜在表征,用于“想象—评估—执行”的一体化闭环。
—————————————————————————————————————————————————————————————————————————————————————————
🧩 策略学习:从 MLP/Transformer 到 Diffusion/Flow/SSM
本节导读:策略是“怎么做”的大脑。不同范式在实时性、稳健性、训练成本上各有取舍。
建议按时延预算、动作多峰性、可解释/合规需求做选型(DP 工程成熟;FM 更快更顺滑;SSM 长序列性价比高)。
1️⃣ 基础自回归策略
2️⃣ 扩散策略(Diffusion Policy)
3️⃣ 流匹配(Flow Matching)
4️⃣ 状态空间模型(SSM / Mamba)
✅ 小结:DP → FM → SSM 是策略层的三条主线。
DP 工程成熟;FM 推理更快;SSM 在长时依赖与效率间平衡。
—————————————————————————————————————————————————————————————————————————————————————————
📦 数据:采集—利用—扩展—重加权
本节导读:数据决定上限,策略决定下限。构建低成本、持续化的数据飞轮,是小团队突围的关键。
从遥操/合成冷启动,依靠选择/检索/增广/扩展/重加权滚动提效,最后接在线纠错闭环。
采集方式
RoboTurk:众包远程遥操。
MimicGen / DexMimicGen:系统化示范合成。
AnyTeleop:多形态视觉遥操。
DemoGen:全合成示范生成。
数据利用与优化
选择/清洗 → 检索 → 增广 → 扩展 → 重加权;
冷启动靠检索,规模化靠增广,鲁棒性靠重加权。
—————————————————————————————————————————————————————————————————————————————————————————
🌍 泛化:环境 / 任务 / 跨具身
本节导读:泛化不是“自动出现”,需要评测协议 + 结构性先验。
分别从环境、任务、具身差异三条线补齐方法与验证,避免“单场景过拟合”。
环境泛化:Sim2Real 综述
任务泛化:层级策略、语义分解、可重组技能、元学习。
跨具身:Open-X-Embodiment | AnyBimanual
—————————————————————————————————————————————————————————————————————————————————————————
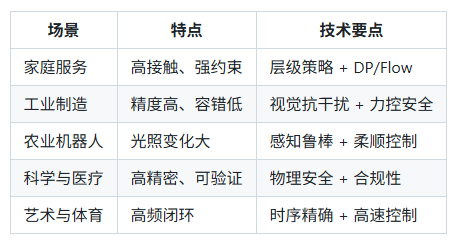
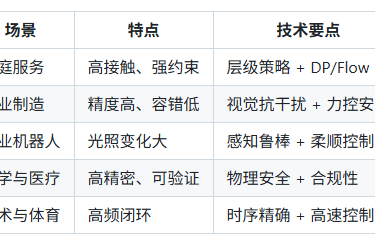
🏭 典型应用:家务、工业、农业、AI4Science、艺术与体育
本节导读:不同场景的约束、容错、合规差异很大。
这里给到每类应用的技术侧重点,方便你对号入座做最小可行方案(MVP)
—————————————————————————————————————————————————————————————————————————————————————————
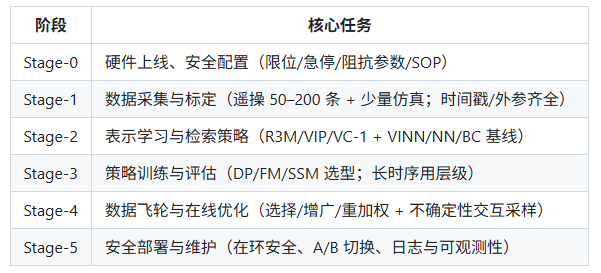
🧭 落地攻略:一条可执行的端到端流水线
本节导读:这是一份可直接执行的路线图。每个阶段都有目标—动作—产出,便于周/双周节奏推进与复盘。

—————————————————————————————————————————————————————————————————————————————————————————
🔮 开放问题与未来方向
One Brain, Multiple Embodiments:通用大脑支持多形态机器人。
自采—自训闭环:标准化数据协议与价值评估。
多模态深度交互:高分辨触觉与异步多率融合。
安全与协作:规则/MPC + 学习策略的混合范式。
—————————————————————————————————————————————————————————————————————————————————————————
1.3 世界模型综述指引
参考综述:Understanding World or Predicting Future? A Comprehensive Survey of World Models
GitHub 项目主页:https://github.com/tsinghua-fib-lab/World-Model
这份指引适合作为你阅读清华这篇世界模型综述时的「路线图」:
先搞清楚世界模型在解决什么核心问题,再按「历史 → 分类 → 决策 → 应用 → 开放问题」的顺序去看。
—————————————————————————————————————————————————————————————————————————————————————————
1.3.1 核心问题与主要贡献
1.3.1.1 世界模型到底在做什么?
作者把世界模型的核心功能归结为两类:
理解世界(Understanding World)
通过构建外部世界的隐含表示,掌握世界运行机制、因果结构和状态空间。
更偏向「内在表征 + 认知地图 + 常识/社会知识」维度。
预测未来(Predicting Future)
面向物理世界/场景,预测未来状态演化,支持决策与规划。
典型体现:视频生成模型、具身环境模拟器等。
1.3.1.2 主要贡献
提出新的分类框架:以“理解世界 vs 预测未来”作为世界模型的两条主线。
按应用领域梳理技术进展:重点分析自动驾驶、机器人、社交仿真三大领域各自如何利用世界模型。
提出开放问题与未来方向:包括物理规律、社会维度、Sim2Real、效率与安全等。
—————————————————————————————————————————————————————————————————————————————————————————
1.3.2 世界模型的历史与概念背景
早期思想源头
Minsky 的 frame representation(框架表示):用结构化知识来表示世界。
Ha & Schmidhuber(2018)神经网络世界模型:用潜在空间模拟环境动态,重新激活“world model”这一术语。
心理学与认知科学基础
对应「心理模型」「认知地图」理论:人类通过抽象元素和关系来理解世界,而不是逐像素还原。
基于模型的强化学习(MBRL)
世界模型 ≈ 状态转移 + 奖励函数,用于在内部模拟中进行试错和规划。
典型操作:在潜在动态模型上滚动未来轨迹,配合 MPC/MCTS 等生成策略。
LeCun 的 JEPA 框架
引入“快系统(System 1)” vs “慢系统(System 2)”:
快:本能反应,无需世界模型。
慢:需要模拟未来、预测长期后果 → 依赖世界模型。
大语言模型中的世界知识
预训练后,大模型自动习得空间、时间、因果、社会规则等潜在知识。
出现「空间/时间神经元」「认知地图结构」,可视为一种世界模型雏形。
—————————————————————————————————————————————————————————————————————————————————————————
1.3.3 世界模型的两大类:定义与目标
1.3.3.1 隐含表示型世界模型(Understanding World)
目标:学习紧凑、结构化的世界表示,支持推理与决策。
方法特点:
将高维感知输入(图像、点云、文本)压缩为潜在变量。
在潜在空间做预测、规划,而不是在原始像素空间直接决策。
典型关联:
MBRL 中的环境模型
LLM 中的世界知识与认知地图
视觉 / 3D 表示、语义场景图等
1.3.3.2 未来预测型世界模型(Predicting Future)
目标:给定当前观测和可能动作,生成未来状态轨迹。
方法特点:
视频预测 / 视频生成模型(如 Sora)
具身环境模拟器(如 UniSim、Pandora 等)
关键要求:
长期一致性(long-horizon prediction)
物理规律合理性
支持交互与控制(不是纯“看电影”)
—————————————————————————————————————————————————————————————————————————————————————————
1.3.4 世界模型 × 决策:MBRL 与 LLM-Agent
1.3.4.1 MBRL 中的世界模型
模型学习
确定性模型:最小化真实状态和预测状态的 MSE。
概率性模型:最小化预测分布与真实动态分布的 KL 散度。
大量工作在做:representation learning + latent dynamics。
策略生成
MPC:在 learned model 上滚动优化动作序列。
MCTS:在模型构造的搜索树中评估状态价值。
1.3.4.2 LLM 作为世界模型或组件
直接生成行动
LLM 根据场景描述直接输出行动序列 / 指令(如机器人指令、API 调用)。
模块化集成
LLM 负责高层决策 / 任务分解;
底层由专门的 planner 或 MBRL 控制。
示例:用 GPT-4 自动生成 PDDL,再交给传统规划器。
具身环境中的 LLM-Agent
在 VirtualHome 等环境中,LLM 通过交互形成“记忆”与“信念”,据此规划下一步行为。
多模态世界模型 + LLM
学习同时预测未来文本和图像表征,通过 model-based replay 学策略。
将 LLM 推理视作 MDP 中的一种 actor-critic 或 in-context 更新机制。
—————————————————————————————————————————————————————————————————————————————————————————
1.3.5 世界知识:从全球物理到社会心理
作者把 LLM 中的世界知识拆成三块:
全球物理世界知识
时空知识、地理知识、宏观常识。
有工作发现 LLM 中存在「空间/时间神经元」,可编码全球尺度信息。
问题:城市级别知识往往粗糙,需要专门方法精调。
局部物理世界知识(认知地图)
通过局部路径探索,构建环境的全局表示,用于导航与物体定位。
从原始 3D 点云构建带语义标签的 3D 场景图,在机器人 / 自动驾驶中尤为关键。
人类社会知识(心理理论)
LLM 在心理理论任务上有一定能力,但在复杂社交失误检测等方面仍有不足。
提升思路:
显式构建社会知识图谱 + Chain-of-Thought 推理;
两阶段提示等框架,提高心理理论任务表现。
—————————————————————————————————————————————————————————————————————————————————————————
1.3.6 预测未来:视频世界模型与具身环境
1.3.6.1 视频生成世界模型
Sora 为代表的模型
多模态(文本 / 图像 / 视频)条件的视频生成。
具备强物理外观模拟能力(光影、材质、动势等)。
局限:因果推理弱,物理一致性有限,可控交互不足。
后续扩展方向
生成更长视频、提升时间一致性。
统一建模多模态输入(动作、视觉、语言)。
强化可控性和交互性,让用户能“改动作,看结果”。
1.3.6.2 具身环境世界模型
按场景类型划分:
室内环境
典型:AI2-THOR、Matterport3D、iGibson 等。
模态逐步丰富:RGB、深度、LiDAR、音频,甚至社交维度(如 GRUtopia)。
室外环境
城市级环境:MetaUrban、UrbanWorld,强调大尺度动态变化。
开放世界平台:MineDOJO,支持资源收集、建设、生存等长期任务。
动态生成环境
使用生成模型实时构造场景:
UniSim:条件生成机器人操作视频序列。
Pandora / AVID / EVA / Streetscapes 等扩展到人群、城市交通等。
核心趋势:用生成模型做“环境工厂”,以第一人称视角、动作条件预测未来世界。
—————————————————————————————————————————————————————————————————————————————————————————
1.3.7 三大应用场景
1.3.7.1 自动驾驶
经典四模块:感知 → 预测 → 规划 → 控制。
世界模型主要作用于:感知 & 预测。
感知:
由 CNN 发展到基于 Transformer 的多相机 BEV 表示(如 BEVFormer)。
预测:
基于 Transformer 的轨迹预测(Wayformer、MTR 等)。
世界模拟器:
传统几何轨迹模拟 vs 新一代视频生成模拟器(GAIA-1、DriveDreamer)。
文本-图像对齐(如 CLIP)用于可控场景生成(controllable scene generation)。
1.3.7.2 机器人
隐含表示
视觉 / 3D 特征、图结构(RoboCraft)、语言任务表示(BC-Z)等。
未来状态预测
把动作预测看作视频生成问题(如 UniPi)。
Sim2Real 与样本效率
DayDreamer 等工作:直接在现实中用世界模型学习控制,降低对仿真的依赖。
1.3.7.3 社交仿真
LLM 驱动的社会世界模型
AI Town:25 个生成式智能体构成沙盒社区,出现群体级 emergent behavior。
S3:模拟信息传播与社交网络动态。
智能体的内部世界
通过“记忆 → 信念 → 决策”形成稳定人格与行为模式(如 Agent-Pro)。
探索合作、资源管理、可持续决策等宏观现象(如 GovSim)。
—————————————————————————————————————————————————————————————————————————————————————————
1.4 运控综述(人形机器人运动与操控)
本节围绕仿人机器人的**行走(locomotion)与操作(manipulation)**展开,涵盖:
建模与控制、接触规划、模型预测控制(MPC)、全身控制(WBC)、强化/模仿/混合学习、技能表示与基础模型等核心方向。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.1 背景与问题设置
1.4.1.1 仿人机器人与应用场景
仿人机器人具备人类类似的身体结构(躯干 + 双臂 + 双腿),目标是模仿人类形态与功能。
由于形态接近人类,仿人机器人:
更容易从人类演示中获取技能数据;
随着数据与算力扩展,有望形成多功能、强泛化的具身智能体。
应用场景包括:制造业、服务业、人机协作、复杂非结构环境中的任务执行等。
1.4.1.2 双足行走与导航
研究历程:被动行走 → 准静态行走 → 动态行走,逐步纳入外界扰动和负载影响。
关键问题:
在扰动与承载条件下保持稳定行走;
为同时行走 + 操作(loco-manipulation)奠定基础。
导航一般采用分层结构:
全局路径规划器:考虑环境拓扑与长程路径;
局部步态 / 脚步规划器:在局部地形上生成可行步态。
1.4.1.3 全身操作(Whole-Body Manipulation)
全身操作不仅依赖手部,还利用肘部、肩部、躯干、髋部等身体部位进行接触与施力。
难点在于:
感知、状态估计、规划、控制的系统级协同;
高维自由度 + 复杂接触动力学 → 计算开销大。
目标:在复杂接触场景下,实现稳健、安全、有效的多点接触操作。
1.4.1.4 行走与操作一体(Loco-Manipulation)
仿人机器人典型任务往往行走 + 操作同时存在(如开门、推车、搬运)。
要求:
整体、策略性地使用全身;
在完成任务的同时保证平衡与安全;
充分利用所有肢体接触,探索机器人的完整行为空间。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.2 触觉传感与全身触觉
1.4.2.1 触觉传感的重要性
触觉模仿人类皮肤,能在大面积皮肤上提供比本体感受更精细的信息。
优势:
在视觉遮挡时仍可感知接触与物体属性;
感知接触力、粗糙度、纹理、硬度、重量等;
与视觉形成互补:视觉管“看”,触觉管“接触质量”。
1.4.2.2 手部触觉
用于精细操作任务,通常参与力/阻抗控制回路;
基于触觉的 RL:
将触觉信号纳入状态,做端到端策略学习;
挑战:高维触觉输入 + 接触物理模拟困难。
1.4.2.3 足部触觉
用于估计**地面反作用力(GRFs)**与地形属性:
传统使用力矩或负载传感器,但难以获得接触区域、力分布与地形细节。
未来方向:
精确估计硬度、阻尼、塑性、异质性、多孔性等地形属性;
将足部触觉与视觉、IMU 等融合,增强地形理解与足步规划。
1.4.2.4 全身触觉
触觉扩展至手臂、腿部、躯干:
提升平衡控制与碰撞避免;
支持安全的物理人机交互;
在搬运大物体、全身支撑与推挤任务中具有巨大潜力。
挑战:动态感知、多模态融合、实时计算。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.3 多接触规划(Multi-Contact Planning)
1.4.3.1 基于搜索的接触规划
通过状态扩展探索可能配置,创建/打破接触:
常用于腿足机器人步态规划;
搜索过程中需检查碰撞与运动可行性。
为提升效率,引入:
控制变量、重要性采样等方差减少技术;
姿势优化(Pose Optimization, PO):
在给定接触模式下生成全身姿态与运动学配置,
减少搜索维度与计算负担。
1.4.3.2 基于优化的接触规划
将接触动力学纳入轨迹优化中,一次性求解:
接触模式、接触力、接触位置、全身运动。
挑战:
问题规模大、非线性、多约束;
常需使用初值优化、问题分解等加速策略:
例如先做接触规划,再做全身运动规划。
1.4.3.3 基于学习的接触规划
使用 RL 等方法通过试错发现新行为:
常以模块化方式与模型规划器形成层次结构;
可预测质心动力学演化,生成高效接触序列。
未来方向:
更深度的集成方法,将搜索、优化与学习三者优势结合,以兼顾效率与鲁棒性。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.4 模型预测控制(Model Predictive Control, MPC)
1.4.4.1 统一优化视角
MPC 将 loco-manipulation 写成有限时域最优控制问题(OCP):
决策变量:状态轨迹、控制输入、约束力轨迹;
目标:在预测时域内实现稳定、任务完成与接触可行的折中最优。
1.4.4.2 简化动力学模型
为实现高频在线规划,使用简化模型:
单刚体模型(SRBM)、线性倒立摆模型(LIPM)等;
通过线性化或近似降低计算复杂度;
已在如 MIT 仿人机器人上实现高动态动作(如跳跃、特技)。
1.4.4.3 全身动力学模型
质心动力学(CD)与全身动力学(WBD)可更精确地刻画机器人动力学:
支持规划更复杂、多样的运动与互动;
代价是:高维非线性 → 计算量巨大。
1.4.4.4 混合保真度模型
在时间上使用不同精度:
近未来(短时域)采用高保真模型保证精度;
远未来(长时域)采用低保真模型降低开销。
目标:在精度与实时性之间取得平衡。
1.4.4.5 MPC 加速策略
结构利用(structure exploitation)
时间步线性化(successive linearization)
预热(warm start)
采样(sampling-based MPC)
核心目标:在保证稳定性前提下,实现实时可用的高频 MPC 控制。
1.4.4.6 环境与对象交互建模
loco-manipulation 场景中,需同时考虑:
静态环境接触;
被操纵对象的动力学;
动态环境(移动物体/人)。
对接触力与对象行为建模的精度,直接影响控制的安全性与可靠性。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.5 全身控制(Whole-Body Control, WBC)
1.4.5.1 WBC 的角色与任务
目标:生成关节扭矩、约束力与加速度,满足多任务目标:
轨迹跟踪(关节或操作空间);
保持平衡与接触稳定;
满足关节限制与碰撞约束。
典型应用:
简化模型已给出期望轨迹,WBC 将其落到关节层;
在不确定环境中提供鲁棒控制层。
1.4.5.2 动态任务建模
动态任务一般表示为决策变量的线性约束:
关节加速度参考;
操作空间加速度;
质心动量率等。
上层 MPC 通常为 WBC 提供这些任务目标。
1.4.5.3 封闭式方法(Closed-Form)
通过逆动力学与约束投影消除接触力:
优点:计算快、结构清晰;
缺点:难以处理不等式约束(如关节限位、障碍物)。
1.4.5.4 优化方法(QP / 层次 QP)
使用 QP 或多级 QP 解决 WBC:
支持多个动态任务与不等式约束;
严格任务层次(按优先级顺序求解子问题);
或通过加权 QP 实现软优先级。
在 loco-manipulation 中,WBC 必须同时确保运动目标与瞬时平衡。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.6 移动与操作技能学习:RL / IL / 混合
1.4.6.1 强化学习(RL)
特点:
不依赖示范数据,通过试错探索未知行为;
可从原始感知输入直接输出动作。
挑战:
奖励设计困难,尤其在复杂任务中;
sim-to-real 迁移难;
高维系统与稀疏奖励 → 学习效率低。
提升策略:
课程学习(逐渐提升任务难度);
好奇心机制(鼓励探索未见状态);
约束 RL(用约束替代部分奖励,简化调参)。
迁移技巧:
域随机化(Domain Randomization, DR);
系统识别(System ID, SI);
域适应(Domain Adaptation, DA)。
应用:动态行走、跳跃、爬楼梯、非周期运动(如跑酷)。
1.4.6.2 模仿学习(Imitation Learning, IL)
数据来源:
专家策略执行的轨迹;
人类遥操作(teleoperation),提供平滑自然的示范。
方法:
行为克隆(BC):监督学习复制专家行为;
逆强化学习(IRL):从数据恢复奖励,再配合 RL 训练策略。
多模态分布:
遥操作数据往往多模态(多种可行动作);
引入如 Action Chunking Transformer(ACT)等模型,处理多样动作分布。
结论:
虽然采集高质量数据成本高,但从机器人经验中学习仍是获得专家级性能的主流路线。
1.4.6.3 从人类数据中学习
数据来源:
运动捕捉系统(高质量 3D 动作,但成本高且难扩展);
互联网视频(规模大但噪声重);
动画数据(可控制但缺少真实物理多样性)。
核心挑战:
身体比例 / 构型差异(human ↔ robot);
缺乏力觉、触觉信息,难以直接学习复杂物理交互。
方法:
动作重定向(retargeting):在关节或任务空间映射人类动作到机器人;
在物理仿真中验证可行性;
使用对抗模仿(GAIL、AMP)等方法学习类人行走、跳跃等。
方向:
更高保真仿真、更实惠/可靠的机器人硬件;
利用互联网规模数据集扩展运动能力与泛化性。
1.4.6.4 混合方法(Hybrid:RL + IL + MPC)
典型模式:
先用 RL 在仿真中训练教师策略,再用 IL 让学生策略在硬件上运行;
或先用 IL 预训练策略,再用 RL 在不同环境下微调。
MPC + RL:
MPC 生成参考轨迹,RL 学 residual 或模仿轨迹;
兼顾轨迹可解释性与策略灵活性。
结论:
混合方法结合了模型方法的稳定性和学习方法的涌现能力,是当前工程实践中很有潜力的方向。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.7 技能表示与组合
1.4.7.1 显式表示与隐式表示
显式:直接以状态-动作轨迹表示单个技能;
隐式:编码在网络结构与参数中,更易组合与泛化。
1.4.7.2 技能组合方式
专家混合(Mixture of Experts, MoE):
先训练多个专家策略,再由高层策略选择/混合;
可实现技能间平滑切换,但容易出现专家不平衡。
结构化表示:
利用运动表示、目标表示、状态转移表示等方式,让一个策略支持多任务:
运动表示:用生成模型(VAE、GAN 等)将高维动作编码到低维潜在空间;
目标表示:用向量编码来自图像/语言/演示的任务目标,形成 goal-conditioned policy;
状态转移表示:在潜在空间中建模 MDP 动力学,即世界模型(World Models),可生成虚拟数据、提升数据效率,并缓解 sim-to-real 问题。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.8 基于学习的全身运动与操作
全身运动/操作任务要求:
稳定接触;
精确接触力控制;
高维复杂物理场景下的可靠性。
现状:
许多 RL/IL 方法在仿真中已能展示复杂全身技能;
真实机器人上的迁移仍较困难。
常见策略:
RL 中精心奖励设计 + 课程学习 + 约束;
IL 中通过遥操作和人类数据收集高质量轨迹;
混合方法中使用 MPC 提供参考、RL 学灵活技能。
展望:
学习方法有能力在无结构场景中发现模型方法难以显式编码的涌现行为;
未来重点在于提升真实世界鲁棒性与安全性。
—————————————————————————————————————————————————————————————————————————————————————————
1.4.9 基础模型在仿人机器人中的应用
1.4.9.1 预训练 LLM / VLM 作为组件
预训练模型不直接输出低层动作,而是:
提供任务中间表示(规划、代码、奖励、子目标等);
由低层控制器执行具体动作。
常见模式:
SayCan:用价值函数对候选动作排序,保证物理可行;
将 GPT-4 等输出限制在技能库中可执行的 primitive 范围。
1.4.9.2 仿人基础模型(Robot Foundation Models, RFM)
目标:从互联网规模机器人数据中预训练多模态模型,直接感知—决策—行动闭环。
主要挑战:
数据:收集足够高质量仿人数据难度大;
动力学:仿人平台动态不稳定,维度高;
训练与推理成本高,需要高效算法与硬件加速;
模型与传统控规系统的接口设计。
—————————————————————————————————————————————————————————————————————————————————————————
1.5 具身导航综述(Embodied Navigation)
本节围绕「具身导航(Embodied Navigation)」展开,重点梳理:
从传统导航到感知空间的理论基础、几何与语义感知、几何方法 vs 学习方法、效率优化策略,以及具身导航支撑的一系列典型任务与未来挑战。
—————————————————————————————————————————————————————————————————————————————————————————
1.5.1 问题定义与研究背景
1.5.1.1 从传统导航到具身导航
传统导航范式
基于绝对坐标系(经纬度 / UTM 等);
有完整地图、精确定位(GPS/GNSS/DGPS)、路径规划(最短路径 / 最小时间 / 最小成本);
典型应用:军事、交通运输、物流、卫星与航海等。
新兴需求带来的范式转变
无 GPS 场景:水下、地下、城市峡谷、室内等;
无地图场景:未探索区域、动态环境;
任务导向场景:目标是“完成任务”而非“走某条固定路线”。
具身导航的核心思想
导航主体是具身智能体(embodied agent):带身体、带传感器、可以行动与交互;
通过与真实世界交互获得局部地图 / 位置感 / 任务语义,在不完美信息下完成导航任务;
物联网(IoT)与 AI 的发展,使从“绝对地图+定位”走向“感知 + 交互 + 决策”的具身导航成为可能。
1.5.1.2 研究目标与结构
系统目标
感知:构建从传感器到世界的几何 + 语义表示;
导航:在复杂环境中规划动作、控制运动;
效率:在算力、能耗、延迟约束下仍可实时运行;
任务:在自动驾驶、家庭服务、仿生机器人、微观机器人等多种场景中可靠落地。
—————————————————————————————————————————————————————————————————————————————————————————
1.5.2 感知:从物理空间到感知空间
1.5.2.1 理论基础:传统导航三要素
地图绘制
场景:地图投影(圆柱 / 墨卡托)、遥感、摄影测量、GIS 等;
目标:构建精确的世界几何模型。
定位技术
三角测量:ToA / TDoA / AoA;
卫星定位:GPS、北斗、GNSS、DGPS;
基于地标和锚点的定位。
路径规划
图论方法:最短路径、最小成本、最大流等;
在导航中形成“图 + 权重 + 优化目标”的标准范式。
1.5.2.2 感知空间与等距性
感知空间(Perception Space)
由多模态传感器信号构成的向量空间:WiFi 信号强度、IMU、图像、激光点云等;
形式上是一个带范数的完备向量空间(Banach 空间)。
与物理空间的一致性
存在一个感知子空间,与物理空间 (\mathbb{R}^3)等距同构;
即存在距离保持映射 (f):感知空间 → 物理空间,使得在感知空间中可支持几何类导航。
直观理解:只要感知足够丰富且连续,就能在“感知空间里走路”,同时在“物理空间里走对路”。
1.5.2.3 几何感知:从 SLAM 到目标定位
SLAM(Simultaneous Localization and Mapping)
目标:在未知环境中一边建图、一边定位;
典型子模块:
里程估计(odometry):视觉 / LiDAR / 惯性 / 无线电等;
回环检测(loop closure):发现“又回到了老地方”;
后端优化:MAX/MAP / 最小二乘,优化位姿图和地图。
SfM(Structure from Motion)
从无序图像集合重建环境结构;
更偏向离线、高精度、大规模重建,可为自定位/导航提供高质量地图。
自定位(Localization)
在先验地图上,用当前观测匹配位置;
视觉定位:图像检索 + 特征匹配 + 几何求解;
无线定位:WiFi / RFID / 信号指纹。
目标定位(Target Localization)
任务是:找到“要去的那件东西/地方在哪儿”;
方式:声源定位(音频)、RFID 标签定位等。
1.5.2.4 语义理解:从像素到“可用信息”
语义标注(Semantic Segmentation)
为每个像素/体素赋予语义标签(地面、墙、桌子、车、人…);
CNN 时代 → Transformer 时代:后者在长程依赖和上下文理解上表现更强。
语义关系(Semantic Relations)
识别实体之间的关系:如“杯子通常在桌子上”,“微波炉常在厨房墙边”等;
典型技术:贝叶斯记忆、图卷积网络(GCN)、Transformer,用于构建“语义图”。
超语义(Hyper-Semantics)与多模态融合
视觉 + 语言 + 声音等多模态协同:
VLN(Vision-Language Navigation);
利用语音 / 音频事件指引导航;
多模态融合构建更丰富的场景表示。
—————————————————————————————————————————————————————————————————————————————————————————
1.5.3 导航策略:几何 vs 学习
1.5.3.1 几何方法
基于地图的导航
构建占据栅格 / 语义地图;
使用 A*、D* 等进行路径搜索;
结合 SLAM 实现「边建图边导航」;
新趋势:引入多尺度碰撞地图、势函数等思想,提升探索效率和鲁棒性。
基于图的导航
环境表示为图:节点=关键位置 / 拓扑节点;边=可行行走路径;
早期工作:TOUR 模型等“认知地图”理论;
近期发展:
网格 + 拓扑混合表示;
GCN 等深度图模型用于学习导航策略和价值函数。
1.5.3.2 基于学习的方法
强化学习与模仿学习
RL:通过试错最大化累积奖励,适合未知环境;
IL:通过人类/专家演示直接学习策略;
典型做法:
利用语义地图 + 辅助任务提升样本效率;
通过众包平台收集大规模人类演示(如 Web-based 环境)。
视觉语言模型(VLM)与大型语言模型(LLM)驱动导航
VLM:将图像与文本嵌入到统一语义空间,用于“自然语言描述的目标导航”;
LLM:作为高层规划器,解析自然语言指令,输出子任务 / 子目标 / 代码:
利用 CLIP 类模型实现零样本导航;
利用 GPT 系列对复杂视觉-语言任务进行推理;
结合 VLMaps 等,将 VLM/LLM 提供的语义嵌入对齐到几何地图上。
1.5.3.3 方法对比与结合
几何方法
优点:几何精度高、可解释性强、路径最优性有理论保障;
缺点:语义理解有限,对动态/未建图环境适应性差,实时更新成本高。
学习方法
优点:适应性强,能利用大规模数据和语义先验,适合复杂任务;
缺点:依赖大量训练数据,训练/推理成本高,鲁棒性与安全性需要额外保证。
趋势:几何 × 学习深度融合
几何方法提供结构与约束,学习方法提供策略与语义;
世界模型 / VLA / LLM-Agent 等框架中,两者正逐步统一。
—————————————————————————————————————————————————————————————————————————————————————————
1.5.4 具身导航的效率优化
具身导航的部署环境通常受限于计算、能耗、通信与实时性,因此需要专门的优化策略。
1.5.4.1 延迟优化
自适应计算(Adaptive Computation)
模型调度与资源感知:
根据当前算力/负载在多种模型配置间切换;
为移动端/机器人提供不同精度 — 开销的模型族;
模块化模型扩展与弹性化架构:
网络可按层 / 分支裁剪,以适应不同时间预算。
并行与专用硬件
利用 CPU/GPU/NPU/FPGA 等异构硬件并行执行感知与决策;
多分支结构、事件驱动算法、算子融合等技术减少内存访问与延迟。
通信优化
边缘计算与任务卸载:将部分 SLAM/感知任务卸载至边缘服务器;
数据压缩、选择性传输:只传输紧凑的环境表示或关键帧;
紧凑地图/环境表示:如局部特征图、语义 keyframe。
1.5.4.2 能效优化
问题来源
动态环境下频繁重规划;
复杂路径规划算法的高算力消耗;
无人机、移动机器人等对续航极为敏感。
代表性策略
在规划目标中显式引入“能耗最小化”;
混合进化算法 / 深度 RL 优化速度、轨迹和避障距离;
从统计数据中建模“路段能耗分布”,用贝叶斯方法优化路径。
1.5.4.3 鲁棒性提升
对环境变化的适应
数据增强、自监督适应、测试时适应(TTA);
在线微调 / 域对齐,平衡适应速度与稳定性。
提升传感器安全与可靠性
对抗攻击检测与防御:利用轨迹注意力、多模态一致性来发现异常;
多模态感知融合:视觉 + 音频 + IMU 等,增强对噪声与攻击的鲁棒性。
—————————————————————————————————————————————————————————————————————————————————————————
1.5.5 具身导航支撑的典型任务
1.5.5.1 自动驾驶
多模态感知:摄像头 + LiDAR + 雷达 + V2X;
实时环境理解:车道、行人、车辆、交通标志等;
动态路径规划:在拥堵、施工、事故等情形下重规划;
安全决策:碰撞避免、行人为先、遵守交通规则。
具身导航在这里体现为:车体 = 具身智能体,在复杂交通系统中完成感知 → 预测 → 规划 → 控制的闭环。
1.5.5.2 通用助理机器人
家庭 / 工厂 / 仓储等场景的导航 + 操作一体化:
例:TidyBot 根据用户偏好整理物品;
例:OK-Robot 利用 VLM 做零样本物体检测与导航。
结合 LLM/VLM 的任务理解与规划:
SayCan 引入可执行性函数,将 LLM 输出和环境可行性约束结合;
Inner Monologue 通过“内省”提升任务规划稳定性;
Code-as-Policies 通过 LLM 直接生成机器人策略代码。
核心趋势:语言 → 代码/子任务 → 具身导航 + 操作 的端到端任务线。
1.5.5.3 导航 × 问答(Embodied QA / IQA)
Embodied QA(EQA):智能体在 3D 环境中导航,再根据第一人称视觉回答问题;
Interactive QA(IQA):允许智能体通过打开门、移动物体等操作获取新信息;
Multi-Target EQA:在同一环境中围绕多个物体 / 位置提出复杂问题;
PaLM-E 等多模态大模型提升了“看 + 想 + 走 + 答”的整体能力。
1.5.5.4 仿生导航
仿生鱼
使用软体结构与分布式电子系统适应深海高压;
未来可在具身导航框架下执行深海采样、监测任务。
仿生昆虫
模仿昆虫腿部机构,实现快速、小型、灵活运动;
应用于基础设施巡检、环境监测、精准农业等。
多环境机器人
受乌龟等启发的“水陆两栖”机器人;
在陆地和水下自由切换,实现多场景任务。
形态变化机器人
受章鱼、蠕虫启发的软体机器人,可根据任务改变形态;
例如在毫米级管道中前进的机器人,用于检修、搜救等。
1.5.5.5 微观环境导航
医疗场景
微型机器人在血管中导航,进行靶向药物输运;
在外部磁场与实时成像引导下到达肿瘤等目标区域。
水体污染治理
磁性/光驱动微纳机器人在水体中导航,吸附与降解污染物;
利用导航技术实现对纳米塑料、重金属等的精准清除。
—————————————————————————————————————————————————————————————————————————————————————————
2. 各技术学习路线(Roadmaps)
贡献者:@KandS
每条路线 = 前置要求 → 4–8 周分周计划 → 里程碑 → 作业与验收 → 延伸阅读
目录
通用路线模板
样板 A|Diffusion Policy 路线(可直接用)
前置:Python/PyTorch;理解轨迹/动作参数化
周程:train_dp.py 跑通 → 更换视觉编码器(SigLIP)/动作表示 → 加入遥操作数据,完成桌面抓取
里程碑:成功率≥80%,采样/去噪可视化
坑:时间对齐、动作尺度、采样步数引入时延
延伸:DP/ACT/LEAP;Bridge/RT-*;W&B/TensorBoard
样板 B|VLA 路线(OpenVLA/π0/RT-2 思路)
前置:Transformer、CLIP/SigLIP
周程:最小 Demo(回放推理)→ 换编码器/提示/动作 token 化 → 多步骤指令任务
里程碑:多指令可控 Demo + 评测脚本
坑:动作对齐、长序列退化、指令歧义
延伸:OpenVLA/RT-2/π0;Hydra/Accelerate/LoRA;Bridge/Libero/Open-X
—————————————————————————————————————————————————————————————————————————————————————————
2.1 强化学习
前置要求:Pytorch / 马尔可夫决策过程(MDP)
理论:
基础:Q-learning → DQN → REINFORCE → Actor-Critic → PPO
课程:
OpenAI Spinning Up in Deep RL:提供 REINFORCE、TRPO、PPO、DDPG、TD3、SAC 等算法的理论讲解与实现
实践:
工具:
Stable-Baselines3 :实现 DQN、PPO、A2C、TD3、SAC 等算法,广泛用于 RL 实验,兼容 Gym
Gymnasium:提供 CartPole、MountainCar、LunarLander 等经典任务,用于入门测试
最小目标:使用 PPO 训练智能体,完成 CartPole 平衡杆任务
进阶目标:探索稀疏奖励情境下的 MountainCar 爬坡车任务
延伸:
—————————————————————————————————————————————————————————————————————————————————————————
2.2 模仿学习
前置要求:PyBullet / 强化学习
理论:
基础:BC → DAgger → GAIL
课程:
CS285 深度强化学习课程(UC Berkeley):包含 DQN、REINFORCE、PPO、DDPG、SAC、BC、DAgger 等算法的完整作业和实现
实践:
延伸:
项目:
Diffusion Policy:基于扩散模型的策略学习方法,适用于高维动作空间的机器人控制任务
DP3 :将 3D 视觉表示与扩散策略相结合
HumanPlus:人形机器人系统,融合了模仿学习、强化学习和影子学习技术
工具:
—————————————————————————————————————————————————————————————————————————————————————————
2.3 3D 视觉
前置要求:OpenCV / PyTorch / 基础线性代数与几何
理论:
基础:2D/3D 视觉分割(Mask R-CNN/PointNet) → 6D 姿态估计(PoseCNN/CosyPose) → 手眼标定 → 抓取策略 (2D/6D)
课程:
《动手学深度学习》中文版:提供PyTorch实现的CNN等深度学习基础
OpenCV-Python 中文教程:涵盖图像处理、特征提取等CV基础
实践:
工具:
Detectron2:支持Mask R-CNN等先进检测与分割算法
Open3D-ML:专注于3D机器学习任务,如语义点云分割
PyBullet:轻量级物理仿真平台,用于搭建机械臂抓取实验环境
最小目标:使用 Detectron2 在自定义数据集上训练一个实例分割模型
进阶目标:在 YCB-Video 数据集上复现 PoseCNN,完成物体 6D 姿态估计
延伸:
项目:
GraspNet-1Billion:大规模抓取数据集与基线模型
Dex-Net 2.0:基于物理的抓取评分与规划框架
Tac2Pose:视觉与触觉融合的姿态回归方法
工具:
—————————————————————————————————————————————————————————————————————————————————————————
2.4 规划与控制
前置要求:ROS / 线性代数 / 基础微积分
理论:
基础:正运动学(DH参数) → 逆运动学(解析/数值解法) → 动力学建模(Lagrangian/Newton-Euler) → 采样法规划(PRM/RRT) → 轨迹生成与平滑(B样条) → 经典控制器(PID) → 阻抗控制 → 模型预测控制(MPC)
课程:
《机器人学:规划、控制及应用》:开源中文学习指南,涵盖运动学、动力学、控制等核心内容
《Modern Robotics》配套代码库 (C++):提供《Modern Robotics》一书的C++实现,注释为中文,便于理解
ROSBOT:汇总了ROS机器人开发的相关资料,包含运动学模型、路径规划算法(Dijkstra, A*, RRT)、ROS常用命令等内容
实践:
工具:
Gazebo:真实物理模拟环境,用于验证控制器效果
nobleo/path_tracking_pid:基于 ROS 的 PID 路径追踪控制器,支持平滑路径追踪与多种测试用例
最小目标:使用 DH 参数描述一个 2-DOF 或 6-DOF 机械臂,并实现其正/逆运动学模拟器
进阶目标:在 Gazebo 中仿真 UR5 机械臂,实现基于 PID 的轨迹跟踪控制,并可视化运动路径
延伸:
项目:
modulabs/arm-control:支持 Elfin 6 机械臂的 ROS 轨迹一体化控制框架,包含多种控制器和 Gazebo 仿真
ferasboulala/five-dof-robot-arm:使用 ROS + MoveIt! 驱动 5 DOF 机械臂,支持 Gazebo 仿真与 Arduino 物理执行
JZX-MY/psolqr_local_planner:ROS 本地路径规划插件,实现 PSO 优化 + LQR 控制一体设计
itsahmedkhali/MobileRobotEKF-LQR:差分驱动机器人项目,使用EKF 做状态估计,LQR 做控制,并在 Gazebo & ROS 中仿真
工具:
MATLAB Simulink:用于MPC等复杂控制器的快速原型验证
—————————————————————————————————————————————————————————————————————————————————————————
2.5 定位与导航
前置要求:ROS / 基础概率论与线性代数
理论:
基础:状态估计理论(贝叶斯滤波、卡尔曼滤波、粒子滤波) → 位姿图优化(Pose Graph / Factor Graph) → 图搜索算法(Dijkstra, A*, D* Lite) → 随机采样法(RRT, PRM) → 优化方法(MPC, CHOMP, TEB)
课程:
MIT 6.141 / UZH V-SLAM 公开课:提供SLAM的系统性理论讲解
Stanford CS237A (Autonomous Driving):涵盖路径规划的基础理论与应用
实践:
工具:
Cartographer ROS:Google 出品的 2D/3D 激光 SLAM 框架,支持 TurtleBot2 等平台
MoveIt + OMPL:用于机械臂高维空间路径规划
LVI-SAM:激光+视觉+IMU 的 SLAM 系统
teb_local_planner:基于最优控制的局部路径规划器,常用于 ROS 导航
最小目标:使用 Cartographer 搭建 TurtleBot 2D 激光 SLAM 导航系统;使用 OMPL 创建高维路径规划任务
进阶目标:用 LVI-SAM +TEB 在非结构化环境中实现实时导航
延伸:
项目:
VINS-Fusion:清华出品的多传感器融合SLAM系统,支持双目、IMU、GPS
DSO (Direct Sparse Odometry):直接法视觉里程计,适用于特征点稀疏场景
VINS-Mono:单目+IMU的滑动窗口优化实现
Multi-Robot Exploration:多机器人协作探索与地图共享系统
工具:
OMPL:开源运动规划库,提供多种采样规划算法
—————————————————————————————————————————————————————————————————————————————————————————
2.6 触觉与力控
前置要求:ROS / 基础力学与控制理论
理论:
基础:刚体动力学与逆动力学 → 力-位置控制(Hybrid Control) → 阻抗控制(Impedance Control) → 导纳控制(Admittance Control) → 优化控制 + MPC → 触觉传感器类型 → 触觉信号处理
课程:
《现代机器人学》:强烈推荐第6章“力/力矩传感”,涵盖力控核心理论
MIT 6.141 Robotics:包含力控基础,适合系统性学习
实践:
延伸:
Feel the Force (FTF):从人类示范中学习力敏感操作的开源项目,结合力控与学习算法,可用于研究机器人在接触任务中的策略生成
HATPIC:开源单轴触觉操纵杆,用于远程操作与力反馈实验,适合自建低成本触觉装置
—————————————————————————————————————————————————————————————————————————————————————————
2.7 VLA
前置要求:Transformer / CLIP / SigLIP / 模仿学习
理论:
基础:Isaac 与 RoboMimic 使用 → Diffusion / Flow Matching 生成策略 → OpenVLA
材料:
Isaac Lab 中文文档:学习任务定义、环境创建与操作演示
Diffusion Policy:基于扩散模型的策略学习方法,适用于高维动作空间。
3D Diffusion Policy (DP3):将3D视觉表示与扩散策略相结合,提升泛化能力。
OpenVLA:开源通用 VLA 模型,基于 SigLIP+DINOV2 视觉编码器和 Llama 2-7B 语言模型
实践:
延伸:
项目:
ALOHA / ACT:低成本双臂机器人系统与配套的动作分块策略,支持长时序任务执行。
RT-1:Google 提出的 Transformer 模型,用于多任务机器人控制
RDT-1B:清华大学发布的 12 亿参数扩散基础模型,支持多机器人操作
n0 (Pi-0):由 Physical Intelligence 提出的 VLA 流匹配模型,支持连续动作块输出
DexVLA:Cornell 大学提出的 VLA模型,通过插入可插拔扩散动作专家提升效率
工具:
Hugging Face Transformers:用于加载和微调大型视觉-语言模型(如SigLIP, Llama)
RoboMimic:模仿学习库,支持行为克隆(BC)等策略,用于模型训练
—————————————————————————————————————————————————————————————————————————————————————————
2.8 Sim2Real
前置要求:ROS / 强化学习
理论:
基础:主流仿真环境(MuJoCo, Isaac Gym, Isaac Sim, PyBullet) → Sim2Sim → 域适应(Domain Adaptation) → 域随机化(Domain Randomization) → 增量网络(Progressive Network) → 逆动力学模型(Inverse Dynamics Model)
材料:
MuJoCo:高性能物理引擎,适合研究和开发
Isaac Gym:用于大规模并行强化学习训练的 GPU 加速平台
PyBullet:轻量级物理仿真平台,用于搭建机械臂抓取实验环境
Tzeng等人 (2015) - Domain Adaptation + 对比学习:通过联合训练实现仿真与现实图像的隐空间对齐
Gupta等人 (2017) - Invariant Representation with Dynamic Time Warping:使用 DTW 对齐模拟与现实状态序列,以迁移 RL 策略
Rusu等人 (2016) - Progressive Nets for Pixels→现实:采用增量网络结构,连接仿真与现实任务
Peng等人 (2018) - Dynamics Randomization:对关键物理参数进行随机采样,训练鲁棒性策略
Tobin等人 (2017) - 视觉领域随机化:对仿真环境中的纹理、光照等进行随机混合,增强视觉模型泛化能力
实践:
工具:
SplitNet:模块化视觉输入与策略结构,适用于 Sim2Sim 视觉迁移
DRL-PPO-sim2sim-imitationlearning:悬臂机器人 Sim2Sim 项目,测试模型在不同环境参数下的迁移能力。
NVlabs/handover-sim2real:实现从仿真到现实的点云驱动机器人交接动作学习
facebookresearch/spot-sim2real:Boston Dynamics Spot 机器人 Sim2Real 框架,支持视觉导航与复杂任务调用
UT-Austin-RobIn/lang4sim2real:结合自然语言提示提升 Sim2Real 迁移效果
anmarr-nabbas/sim2real-ur-gym-gazebo:将 UR5 机械臂在 Gazebo 中训练的 RL 抓取策略迁移到真实环境
mehrab-abrar/Sim2Real (Quadruped):在“Frozen Lake”环境中训练四足机器人策略并迁移到真实实验
最小目标:安装 Habitat + SplitNet,测试 sim-to-sim performance
进阶目标:运行任意 Sim2Real demo,记录仿真与实机的差别;插入增强方法,如 Domain Randomization、逆动力模型或语言提示,比较性能变化
延伸:
Unitree RL GYM:四足机器人跨仿真迁移平台,支持从 Isaac Gym 到 MuJoCo 再到实机的完整流程
Humanoid-Gym:Isaac Gym 上 humanoid locomotion,支持 zero-shot Sim2Real,并提供 Sim2Sim 测试
DRL-PPO-sim2sim-imitationlearning:悬臂机器人 Sim2Sim 项目,测试模型在不同环境参数下的迁移能力
NVlabs/handover-sim2real:实现从仿真到现实的点云驱动机器人交接动作学习
—————————————————————————————————————————————————————————————————————————————————————————
2.9 世界模型
前置要求:强化学习 / 概率建模 / 变分自编码器(VAE)
理论:
基础:
潜在动力学建模(Latent Dynamics Modeling)
世界模型(World Model) → Dreamer → DreamerV2 → DreamerV3
模拟器替代学习(Model-Based RL, MBRL)
材料:
World Models (Ha & Schmidhuber, 2018):提出以 VAE+MDN-RNN 结构学习环境动力学
DreamerV2 (Hafner et al., 2021):基于潜在动力学的 MBRL 算法,能在潜空间中进行长序列规划
DreamerV3 (Hafner et al., 2023):实现跨任务通用性与高样本效率
PlaNet (Hafner et al., 2019):基于潜在空间预测与规划的开创性算法
实践:
工具:
DreamerV3 Official Implementation:作者官方 PyTorch 实现
Planet / Dreamer Reimplementation (PyTorch):支持可并行训练和多环境实验
gymnax:JAX 强化学习环境库,常用于 Dreamer 训练
最小目标:使用 Dreamer 复现 CartPole / Cheetah 环境中的潜在动力学预测;在潜空间进行“虚拟环境”训练
进阶目标:结合 PyBullet 或 Isaac Gym 训练机械臂模型的世界模型,实现从视觉输入预测未来状态,并基于潜在动力学进行规划
延伸:
项目:
DreamerV3 Robotics:将 Dreamer 应用于真实机械臂与移动机器人控制
World Model Policy Gradient (WM-PG):使用潜在空间规划指导 RL 策略学习
MIRAGE:结合世界模型与规划的多模态机器人控制系统
工具:
—————————————————————————————————————————————————————————————————————————————————————————
2.10 数据飞轮与遥操作
前置要求:强化学习 / 模仿学习 / 数据工程基础(数据清洗、标注、版本控制)
理论:
基础:数据飞轮与遥操作概念 → 力反馈遥操作 → AR/VR 远程控制 → 模型辅助示教(e.g. Diffusion Policy Warm-start)
材料:
Tele-operation & Flywheel:数据飞轮与遥操作基础概念博客
PATO:提出“策略辅助遥操作”框架,使人机协作更高效,助力可扩展数据采集
Open-TeleVision:沉浸式视觉遥操作系统,用于高质量示教数据采集
实践:
工具:
ALOHA:低成本双臂遥操作系统,提供数据采集与回放脚本
Open-TeleVision:沉浸式远程控制与反馈系统
最小目标:使用 ALOHA 系统采集单任务(如物体抓取)数据 → 训练一个 BC 策略 → 使用同样系统部署策略并采集新演示数据
进阶目标:构建完整数据飞轮管线:通过 Teleop 采集数据 → 进行自动清洗与标准化 → 使用 Diffusion Policy / OpenVLA 训练模型 → 策略部署到实机 → 新数据自动回流、增强数据集
延伸:
SharedAssembly:通过双操作员共享遥操作系统,提升装配任务数据采集规模与质量
Super-Linear Scaling:通过众包真实场景数字孪生并在仿真中采集数据,实现“人力投入与性能超线性增长”的机器人学习飞轮
DexFlyWheel:提出双臂灵巧操作的数据飞轮机制,从少量人类示范出发,通过 IL + residual RL 实现自增强数据生成。
—————————————————————————————————————————————————————————————————————————————————————————
3. 基础学习(机器人基础|深度学习基础)
贡献者:@mumu-jushen,@KandS 你将获得:机器人学数学基础、深度学习核心机制、工程实践能力;从"坐标变换→运动规划→神经网络→多模态融合"构建知识体系。
目录(Table of Contents)
—————————————————————————————————————————————————————————————————————————————————————————
3.1 机器人学打底:坐标系/运动学/动力学/控制
起步三件事
⭐ 必看:Modern Robotics 第2-4章(坐标系、正逆运动学)
🧪 实作:用Python实现平面二连杆的正逆运动学求解
📦 代码:Robotics Toolbox for Python - Peter Corke的经典工具箱
核心知识点
坐标系与齐次变换
机器人要在空间中精确操作,核心是搞清楚"我在哪,要去哪"。这需要多个坐标系协同:
世界坐标系 {W}:全局固定参考,所有物体位置相对于它描述
基座坐标系 {B}:机器人自身参考系
工具坐标系 {T}:末端执行器(夹爪中心)
物体坐标系 {O}:待操作物体
,
齐次变换矩阵统一旋转R和平移P: 见【代码3-1】(详见 files/formulas/第三节/第三章-代码.md) 串联机械臂从基座到末端的变换矩阵通过连续相乘得到。
正逆运动学
正运动学(FK):关节角度 → 末端位姿 平面二连杆:x = L1*cos(θ1) + L2*cos(θ1+θ2)
逆运动学(IK):末端位姿 → 关节角度 难点:无解(够不着)、多解(肘向上/下)、奇异点(失去自由度)
DH参数法
用4个参数标准化描述连杆关系:
连杆长度:沿x轴距离
连杆扭角:绕x轴角度
连杆偏距:沿z轴距离
关节角:绕z轴角度
轨迹规划对比


三次多项式保证速度连续,五次保证加速度连续,避免机械冲击。
雅可比矩阵
建立关节速度和末端速度之间的关系: 见【代码3-2】(详见 files/formulas/第三节/第三章-代码.md))
MoveIt框架架构
见【代码3-3】(详见 files/formulas/第三节/第三章-代码.md)
实践要点
坐标变换:变换矩阵表示从A到B的转换,连续变换从右往左读
逆运动学:优先解析解(快),数值解做后备
轨迹规划:简单任务用梯形速度,复杂用五次多项式
MoveIt调试:碰撞太严调 padding,规划失败查起点碰撞
—————————————————————————————————————————————————————————————————————————————————————————
3.2 深度学习打底:Self-Attention与Transformer
起步三件事
⭐ 必看:The Illustrated Transformer - Jay Alammar的可视化讲解
🧪 实作:手撕一个mini Transformer(<500行代码)
📄 论文:Attention Is All You Need - 原始论文
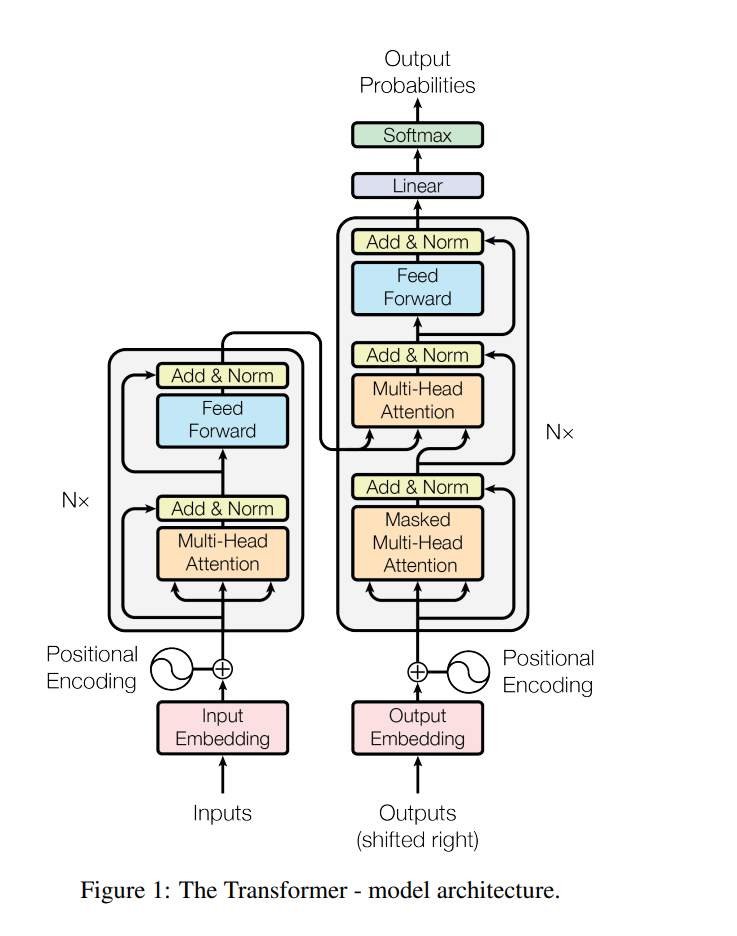
Transformer:从黑盒到掌握全貌
咱先从最简单的视角开始——把Transformer当成一个黑盒子。
第一层理解:纯黑盒
见【图3-1】(详见 files/formulas/第三节/第三章-图片.md)
就这么简单,法语进去,英语出来。别管里面咋实现的,反正它能工作。这就是2017年Google发表《Attention Is All You Need》时震撼世界的原因——这玩意儿把机器翻译的质量提升到了前所未有的高度。
第二层理解:打开盖子看大结构
见【图3-2】(详见 files/formulas/第三节/第三章-图片.md)
掀开盖子,里面是编码器(Encoder)和解码器(Decoder)两大块。编码器负责理解输入,解码器负责生成输出。原论文各用6层,但这不是死的——BERT用12层,GPT-3更夸张用了96层!
第三层理解:单层内部到底干啥
见【图3-3】(详见 files/formulas/第三节/第三章-图片.md)
每一层编码器就干两件事:
Self-Attention:让每个词都能"看到"整个句子的信息
Feed Forward:对每个位置独立做一次非线性变换
这两步都配了"跳线"(残差连接)和"归一化"(Layer Norm),保证信号稳定传递。
见【图3-4】(详见 files/formulas/第三节/第三章-图片.md)
Self-Attention:核心中的核心
为啥需要Self-Attention?
想象你在读这句话:"小明喜欢打篮球,他每天都去球场"。当模型处理"他"这个词时,需要知道"他"指的是"小明"。传统RNN得一个词一个词往前传,传到"他"的时候"小明"的信息可能已经丢失了。CNN只能看固定大小的窗口。
Self-Attention的革命性在于:让序列中任意两个位置都能直接"对话"!
Query-Key-Value机制
见【图3-5】(详见 files/formulas/第三节/第三章-图片.md)
这个机制特别像在图书馆找书:
Query(查询):你想找什么书("我需要关于机器学习的资料")
Key(键):每本书的标签("深度学习"、"统计学习"、"神经网络")
Value(值):书的实际内容
数学上就是: 见【代码3-4】(详见 files/formulas/第三节/第三章-图片.md)
为什么要进行缩放?苏剑林在《浅谈Transformer的初始化、参数化与标准化》里讲得特别清楚——点积的方差会随维度增长,不进行缩放的话softmax会饱和。
注意力可视化
见【图3-6】(详见 files/formulas/第三节/第三章-图片.md)
这图展示了模型在翻译时的注意力分布。比如翻译"The animal didn't cross the street because it was too tired"时,模型需要判断"it"指代什么。通过注意力权重可视化,我们能看到模型确实学会了正确的指代关系。
多头注意力:团队协作
见【图3-7】(详见 files/formulas/第三节/第三章-图片.md)
单个注意力头就像一个专家,多头注意力就是专家团队。假设d_model=512,用8个头,每个头负责64维:
见【代码3-5】(详见 files/formulas/第三节/第三章-图片.md)
不同的头会学到不同类型的关系:
头1:可能专注于局部语法(相邻词关系)
头2:可能捕捉长距离依赖(主语-谓语)
头3:可能学习指代关系(代词-名词)
头4-8:各有分工,语义相似度、句法结构等
位置编码:告诉模型词序
见【图3-8】(详见 files/formulas/第三节/第三章-图片.md)
Self-Attention有个问题——它不知道词的顺序!所以需要位置编码:
见【图3-9】(详见 files/formulas/第三节/第三章-图片.md) 见【代码3-6】(详见 files/formulas/第三节/第三章-图片.md)
为啥用sin/cos?因为它们有个神奇的性质: 见【代码3-7】(详见 files/formulas/第三节/第三章-图片.md)
残差连接与Layer Norm
见【图3-10】(详见 files/formulas/第三节/第三章-图片.md)
每个子层都用了残差连接(借鉴ResNet)+ Layer Normalization:
见【代码3-8】(详见 files/formulas/第三节/第三章-图片.md)
为啥要这么做?
残差连接:防止梯度消失,让深层网络训练更稳定
Layer Norm:稳定每层的输入分布,加速训练
Encoder完整实现
见【图3-11】(详见 files/formulas/第三节/第三章-图片.md)
🧪 实作:手撕一个mini Transformer(<500行代码)
见【代码3-9】(详见 files/formulas/第三节/第三章-图片.md)
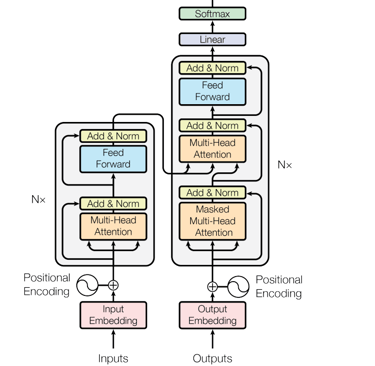
Transformer:从黑盒到掌握全貌
第一层理解:Transformer 是一个黑盒子,输入法语,输出英语,显著提升机器翻译质量。
第二层理解:Transformer 由编码器(Encoder)和解码器(Decoder)组成,原论文各用 6 层,但层数可变(如 BERT 用 12 层,GPT-3 用 96 层)。
第三层理解:每一层编码器包含 Self-Attention 和 Feed Forward 操作,均配备残差连接和 Layer Norm。
见【代码3-10】(详见 files/formulas/第三节/第三章-代码.md)
多头注意力:团队协作
多头注意力是多个专家团队,每个头负责不同维度,学习不同类型的关系(如局部语法、长距离依赖等)。
代码示例展示了如何实现多头注意力,包括 QKV 的计算和多头的合并。
坑1:维度对不上 见【代码3-11】(详见 files/formulas/第三节/第三章-代码.md)
坑2:忘记缩放 见【代码3-12】(详见 files/formulas/第三节/第三章-代码.md)
坑3:位置编码当参数训练 见【代码3-13】(详见 files/formulas/第三节/第三章-代码.md)
坑4:Layer Norm位置 见【代码3-14】(详见 files/formulas/第三节/第三章-代码.md)
为什么Transformer这么强?
并行性
RNN 必须串行处理,第 t 步依赖第 t-1 步
Transformer 可以并行处理整个序列,训练速度飞快
长距离依赖
RNN 信息传递路径长,容易遗忘
Transformer 任意两个位置都能直接交互
表达能力
多头注意力 = 多个特征提取器并行工作
每个头可以学习不同类型的依赖关系
计算复杂度对比
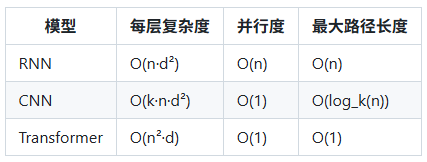
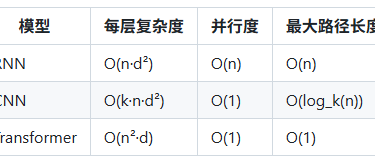
虽然是 O(n²),但对于常见长度(<512),这不是瓶颈。瓶颈通常在d(模型维度)上。
调试技巧总结
先跑通小模型:2 层、128 维度、4 个头,确保流程正确
可视化注意力权重:检查模型是否学到合理的模式
梯度裁剪:torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
学习率warmup必须有:前 4000 步线性增长很重要
检查mask是否正确:打印出来看看,很多 bug 在这
—————————————————————————————————————————————————————————————————————————————————————————
3.3 深度学习打底:优化/正则化/训练技巧
让模型真正学起来:优化器的选择
训练神经网络就像爬山找最低点,优化器决定了你怎么走。
最简单的SGD(随机梯度下降)
见【代码3-15】(详见 files/formulas/第三节/第三章-代码.md)
问题来了——SGD太慢了!就像你走迷宫,每一步都小心翼翼,遇到小坑就卡住了。
带动量的SGD:像滚雪球
见【代码3-16】(详见 files/formulas/第三节/第三章-代码.md)
动量是啥?想象你推一个球下山:
没动量:球在每个小坑都会停
有动量:球有惯性,能冲过小坑继续滚
实际效果对比: 见【代码3-17】(详见 files/formulas/第三节/第三章-代码.md)
Adam:懒人首选
见【代码3-18】(详见 files/formulas/第三节/第三章-代码.md)
Adam聪明在哪?
自适应学习率——每个参数都有自己的学习率
结合了动量——跑得快
几乎不用调参——设lr=1e-3基本就行
具体原理(看不懂可以跳过): 见【代码3-19】(详见 files/formulas/第三节/第三章-代码.md)
什么时候用什么优化器?
做CV(计算机视觉): 见【代码3-20】(详见 files/formulas/第三节/第三章-代码.md)
做NLP或Transformer: 见【代码3-21】(详见 files/formulas/第三节/第三章-代码.md)
做强化学习: 见【代码3-22】(详见 files/formulas/第三节/第三章-代码.md)
学习率调度:训练的节奏感
学习率不能一成不变。就像学车,刚开始大步调整,熟练后要精细控制。
最常用的几种调度器
阶梯式下降(训练CNN常用) 见【代码3-23】(详见 files/formulas/第三节/第三章-代码.md)
余弦退火(比阶梯更平滑) 见【代码3-24】(详见 files/formulas/第三节/第三章-代码.md)
Warmup(Transformer必备) 见【代码3-25】(详见 files/formulas/第三节/第三章-代码.md)
实际使用时,可以用transformers库: 见【代码3-26】(详见 files/formulas/第三节/第三章-代码.md)
样本生成的灵活性
DDPM:由于每一步都添加了随机性,DDPM 的采样过程是不可控的,即使是同样的初始噪声,每次采样的结果也可能不同。
DDIM:通过去掉采样过程中的随机性,DDIM 提供了一种确定性生成机制,即同样的初始条件会生成同样的样本。这对于某些任务非常有用,尤其是需要生成相同的图像或在多次采样中保持一致性时。
DDIM的工作原理
DDIM 的主要目的是在加速采样的同时保留高质量的图像生成。它通过修改扩散模型中的逆扩散过程,从而实现这一目标。
见【代码3-27】(详见 files/formulas/第三节/第三章-代码.md)
加噪过程的数学描述:每个时间步的噪声数据服从高斯分布,通过时间步系数控制噪声强度。
去噪过程 在 DDPM 中,去噪过程反向执行,即从完全噪声的样本开始逐步去除噪声,最终生成原始数据样本。这个去噪过程是逐步且随机的。
见【代码3-28】(详见 files/formulas/第三节/第三章-代码.md)
如何使用DDIM
DDIM 的实现一般依赖于已有的扩散模型(如 DDPM)。只需要调整采样部分的代码即可将 DDPM 的随机采样替换为 DDIM 的确定性采样。
下面是一个简化的伪代码,展示如何在生成过程中使用 DDIM 进行加速采样:
见【代码3-29】(详见 files/formulas/第三节/第三章-代码.md)
效果:模型不会过度自信,泛化性更好。特别是数据有标注噪声时很有用。
混合精度训练:又快又省显存
正常训练用float32(32位浮点数),混合精度用float16(16位),显存省一半,速度快2-3倍!
见【代码3-30】(详见 files/formulas/第三节/第三章-代码.md)
阶梯式下降:每固定步数降低学习率。
余弦退火:学习率像余弦函数一样平滑下降。
Warmup:先小学习率热身,适合 Transformer。
混合精度的坑: 见【代码3-31】(详见 files/formulas/第三节/第三章-代码.md)
—————————————————————————————————————————————————————————————————————————————————————————
3.5 工程环境:Conda/Docker/日志与可视化/复现实验规范
环境管理:让代码在任何地方都能跑
Conda
Conda的基本操作: 见【代码3-32】(详见 files/formulas/第三节/第三章-代码.md)
安装PyTorch的正确姿势: 见【代码3-33】(详见 files/formulas/第三节/第三章-代码.md)
环境导出和复现(重要!): 见【代码3-34】(详见 files/formulas/第三节/第三章-代码.md)
Conda和pip混用的技巧: 见【代码3-35】(详见 files/formulas/第三节/第三章-代码.md)
Docker:终极解决方案
Dockerfile 示例:构建和运行容器,挂载本地目录。
Docker 的坑:Windows 路径问题、GPU 支持、镜像大小。
Conda还是可能出问题(比如系统库不同),Docker是真正的"带环境运行"。
最简单的Dockerfile: 见【代码3-36】(详见 files/formulas/第三节/第三章-代码.md)
构建和运行: 见【代码3-37】(详见 files/formulas/第三节/第三章-代码.md)
Docker的坑:
Windows上路径要用绝对路径,斜杠方向要注意
GPU支持需要装nvidia-docker
镜像会很大(几个G),注意硬盘空间
实验追踪:WandB让你知道哪次实验效果好
训练模型最怕的:跑了100次实验,不记得哪次参数效果最好...
WandB(Weights & Biases)入门
初始化、记录日志、可视化界面。
超参数搜索:贝叶斯优化。
TensorBoard(备选):本地可视化方案。
见【代码3-38】(详见 files/formulas/第三节/第三章-代码.md)
WandB会自动生成漂亮的可视化界面,能看到:
损失曲线
学习率变化
系统资源(GPU利用率、显存)
你记录的所有图片
更高级的用法:
实验可重复性:让结果能复现
论文里说准确率95%,你跑出来85%,是不是很郁闷?
固定随机种子
代码组织:专业的项目结构
别把所有代码都塞在一个train.py里!
调试技巧:快速定位问题
打印shape是第一步
常见错误和解决
多模态融合:让机器人有多种感知
机器人不只有眼睛(相机),还有触觉、关节编码器、力传感器...怎么把这些信息融合起来?
统一到同一个特征空间
最简单的思路——把所有模态都编码成相同维度的向量:
见【代码3-53】(详见 files/formulas/第三节/第三章-代码.md)
然后扔给 Transformer 处理,它会自动学习跨模态关系!
跨模态注意力的实际效果
训练后你会发现神奇的现象:
当文本说"抓取红色方块",视觉注意力会聚焦在红色区域
当力传感器检测到碰撞,文本理解会关注"小心"、"慢速"这些词
关节接近限位时,规划模块会降低相应方向的运动权重
处理不同采样率
现实中各传感器频率不同:
相机:30Hz
关节编码器:100Hz
力传感器:1000Hz
怎么对齐?
图神经网络(GAT):理解场景关系
机器人要理解的不只是"有什么",还要理解"谁和谁有什么关系"。
场景表示成图
想象桌面场景:
节点:每个物体(杯子、书、笔)
边:物体间的关系(接触、遮挡、支撑)
图注意力机制(GAT)
GAT让每个节点通过注意力机制聚合邻居信息:
实际应用:抓取规划
用GAT理解场景,找出最容易抓取的物体:
GAT在机器人中的典型应用
装配任务:理解零件之间的装配顺序和约束
导航规划:理解房间连接关系,找最短路径
人机协作:理解人的动作意图和物体关系
故障诊断:通过组件关系图定位问题源头
关键优势:
自动学习"什么关系重要"(注意力权重)
处理不规则结构(不像 CNN 需要网格)
可解释性好(能可视化注意力)
—————————————————————————————————————————————————————————————————————————————————————————
4. 各技术基础与经典(理论与经典论文/工程)
贡献者:@ptman12
4.1 Imitation Learning(模仿学习)经典算法综述
本节聚焦于模仿学习(Imitation Learning, IL)中的三大经典方法:**行为克隆(Behavioral Cloning, BC)、数据集聚合(Dataset Aggregation, DAgger)、以及生成式对抗模仿学习(Generative Adversarial Imitation Learning, GAIL)**。重点讨论它们的原理、经典论文、数据分布偏移(covariate shift)与误差累积问题,以及它们之间的关系与演进。
1. 行为克隆(BC)
1.1 算法简介
行为克隆将模仿学习视为一个典型的监督学习问题。给定专家演示数据集
,智能体直接训练一个策略 或确定性映射 ,使其在专家所处状态 (s) 下输出与专家动作 (a^*) 接近的动作。 其优化目标常写为:
例如交叉熵损失、回归均方误差等。许多早期工作(如 ALVINN)即采用此方式。 (arxiv.org)
1.2 优点
简单易实现:直接将监督学习技术迁移至策略学习。
在专家演示覆盖面较好、环境状态分布较为稳定的场景下,表现常常不错。
无需额外设计奖励函数、无需智能体与环境反复交互。
1.3 缺点 — 数据分布偏移与误差累积
正如前文所述,BC 的关键短板在于:训练时只见到了专家策略下的状态分布,而部署时智能体策略可能偏离专家,进入“未知”状态区域,导致性能剧降。这个过程往往伴随着误差累积。文献中从“值差异”角度分析,指出 BC 的值差异(在无穷期折扣模型下)是 级别。 (arxiv.org)
换句话说,如果智能体偶尔偏离专家轨迹,一旦进入偏离状态,再恢复到专家轨迹的难度就会变大,错误可能一发不可收。很多实践中,这一问题使 BC 在真实环境(尤其是高维、长时序任务)中表现并不稳定。
2. 数据集聚合(DAgger)
2.1 算法简介
为了解决 BC 的分布偏移问题,DAgger(Dataset Aggregation)在训练过程中允许智能体以当前策略与专家策略混合控制,从而生成新的状态–动作对,并让专家对智能体经历的新状态进行标注。这样,数据集不断 聚合(aggregate) 新状态–动作对,包含智能体可能进入的“偏离”状态,从而缩小训练/部署时状态分布的差距。 典型流程:
初始化 为专家示范数据。
训练策略 在 上。
使用当前 与专家混合运行策略生成轨迹。
对于轨迹中的每个状态 s,令专家标注 ,将 加入 。
重复训练直到收敛。 详见教材中算法说明。 (来源)
2.2 优点
能有效缓解智能体进入“未见状态”时缺乏标注的问题。
通过在线“探索”其策略可能到达的状态,并让专家加标签,从而覆盖更多状态–动作对。
在理论上,为策略的训练损失在其自身状态分布下提供了边界保障。 (arxiv.org)
2.3 缺点与实际考量
需要专家随时可查询:在执行过程中智能体生成新状态时,需要专家实时标注动作,这在许多现实场景中成本较高或不可行。
虽然改进了 BC 的分布偏移问题,但仍可能存在:如果策略已严重偏离,生成状态–动作对的质量可能较低。
在安全敏感任务中,智能体自主探索可能带来风险。相关扩展如 DropoutDAgger 试图引入不确定性估计以控制风险。 (arxiv.org)
3. 生成式对抗模仿学习(GAIL)
3.1 算法简介
GAIL(Generative Adversarial Imitation Learning)借鉴了生成对抗网络(GAN)的思想,将模仿学习转化为一种 匹配专家与政策的状态–动作分布 的问题。
设专家策略产生的状态–动作分布为 ,智能体策略 下对应 。
GAIL 通过训练判别器 来区分「来自专家」与「来自策略」的样本。策略 则作为“生成器”尝试生成专家难以区分的样本。
对应目标近似为:
策略训练通常结合强化学习(如 TRPO)驱动。 (arxiv.org)
3.2 优点
本质上考虑了 分布匹配(而非仅监督拟合专家动作),因此在理论上比单纯 BC 更强。比如,通过 “值差异” 框架表明,GAIL 的误差为 ,好于 BC 的 。 (arxiv.org)
能适应更灵活的行为复制(不仅仅是专家动作的直接复制)——通过交互获得更多样本。
在仿真任务中通常优于 BC。 (来源)
3.3 缺点与挑战
训练不稳定:GAN 式训练容易出现判别器/生成器失衡、模式崩塌等问题。
仍需与环境交互(需要 rollout),对于真实物理系统可能成本高或不安全。
对于真实专家状态–动作覆盖非常稀疏或多模态行为,匹配专家分布仍面临挑战(例如模态丢失)——有研究将其与 (f)-散度最小化框架关联。 (arxiv.org)
3.4 经典论文/引用
Ho, Jonathan & Ermon, Stefano, “Generative Adversarial Imitation Learning”, NeurIPS 2016.
相关综述:Liu, Z. “Generative Adversarial Imitation Learning Benchmarking and …” (来源)
4. 三者关系与误差累积视角总结
4.1 从 BC → DAgger → GAIL 的演进
BC:最为简单、监督学习式,但受限于专家状态分布,容易偏离后累积错误。
DAgger:引入在线采样+专家标注机制,缓解状态分布偏移,但需要专家持续参与。
GAIL:进一步把焦点放在智能体生成状态–动作分布与专家匹配上,通过 adversarial training 实现更强泛化能力。
4.3 实践建议
若演示数据量大、覆盖面广、状态–动作映射稳定、环境变化少:BC 是一个合理起点。
若部署环境复杂、策略偏离风险高、专家仍可参与:推荐使用 DAgger 或其变体。
若环境复杂、专家标注代价高、希望智能体具备较强泛化或生成能力:可考虑 GAIL 及其后续扩展。
在任何方法中,都应关注:演示数据的覆盖质量、智能体训练后可能到达的状态范围、以及对“偏离状态”的监控或补充机制。
5. 总结
模仿学习作为连接专家演示与决策策略的重要范式,其经典方法 BC/DAgger/GAIL 在理论和工程上都起到了标杆作用。理解它们之间的差别、各自的适用场景和限制,有助于在实际系统中进行合理选择与设计。尤其是“数据分布偏移”与“误差累积”这两个核心风险,是选择和改进算法时必须正视的问题。
4.2 RL 经典:值/策略/Actor-Critic,收敛与稳定性
1. 值函数方法(Value-based Methods)
1.1 算法简介
值函数方法主要通过估计状态值函数(V(s))或状态-动作值函数(Q(s,a)),然后由此导出或近似最优策略。典型代表包括 Q‑learning 和 Deep Q‑Network (DQN) 等。 算法一般形式(例如 Q-learning)为:
然后策略取
1.2 优势
在离散状态/动作空间中、或动作空间可枚举时,值函数方法直观、实现简单。
值函数学习利用了动态规划或时序差分 (TD) 原理,往往更新高效。
1.3 收敛与稳定性问题
在有限状态/动作、表格形式(tabular)下,Q-learning 可证收敛于最优 (Q^*)(在适当探索、学习率衰减条件下)。
在函数逼近(尤其是深度网络)情形下,估计 Q 值可能产生“过估计”、“震荡”或“发散”问题。
在结合深度网络时,需特别关注目标网络、经验回放、截断梯度等机制以增强稳定性。
值函数方法在复杂环境中仍可能受限于估计偏差/方差/探索不足的问题。 (arxiv.org)
2. 策略直接优化方法(Policy-based Methods)
2.1 算法简介
策略方法直接对策略 进行参数化,并通过梯度上升(或下降)优化预期累积奖励 。常见的有 REINFORCE (Williams, 1992) 等。其基本更新形式为: 其中 (G) 是一次采样轨迹的回报。策略方法具备自然处理连续动作空间、可直接学习随机策略等优势。
2.2 优势
对连续动作空间原生支持,无需枚举或最大化 Q 值。
可直接优化期望回报,策略可采用随机形式,从而自然包含探索。
有丰富的理论(如策略梯度定理)支持。
2.3 收敛与稳定性问题
策略梯度方法虽然理论上具有收敛保证(在梯度噪声受控、学习率衰减、无函数逼近偏差的情形下),但在实践中往往受到“高方差”、“梯度估计不精确”、“探索/利用难平衡”等困扰。
方差大导致训练不稳定、震荡明显。
在与函数逼近结合时,还可能遭遇 “策略陷入局部最优”、“退化为确定性策略导致停滞” 等问题。
因此,在实践中,通常搭配基准(baseline)、熵正则化、自然梯度或其他稳定化技巧使用。
3. 演员-评论员方法(Actor-Critic Methods)
3.1 算法简介
演员-评论员方法兼具策略优化和值函数估计两者。演员 (Actor) 负责生成动作,评论员 (Critic) 估计值函数,为演员提供信号,以更低方差方式更新策略。典型流程:
Critic 通过 TD 或样本估计当前策略的值函数。
Actor 根据 Critic 的反馈更新策略参数。
重复直至收敛。
这一结构使得策略优化中方差控制更好,学习更高效。 (来源)
3.2 优势
政策梯度方差低于纯策略方法。
支持连续动作、高维状态空间,普遍用于现代深度 RL。
在“在线”情境中,Actor-Critic 结构较为通用。
3.3 收敛与稳定性问题
虽然在表格、小规模模型中可获得理论收敛保证,但在函数逼近/深度网络场景下仍缺乏通用的稳定性证明。
例如,有研究指出:Actor-Critic 方法尽管理论上“通常具有良好收敛性质”,但在现实深度学习场景中仍可能“非常不稳定”或“样本效率低”。 (来源)
针对闭环控制系统(如机器人控制),还需考虑系统“稳定性”(如闭环收敛、扰动鲁棒性)的问题。有工作结合 Lyapunov 方法提出“具稳定性保证”的 Actor-Critic 框架。 (来源)
最新有关两时尺度 Actor-Critic 法的收敛性研究亦在推进中。 (来源)
4. 三者关系、收敛与稳定性视角总结
4.1 三者的关系与演进
值函数方法:通过估计 (Q)/(V) 再导出策略,是 RL 早期经典。
策略方法:直接优化策略,适合连续动作、随机策略场景。
Actor-Critic:融合两者优势,更适合现代深度 RL 应用。
在实际工程中,许多“深度 RL”算法(如 Deep Deterministic Policy Gradient、Soft Actor‑Critic 等)其实是 Actor-Critic 或值/策略混合范式。
4.2 收敛、稳定性的核心挑战
收敛:算法能否在无限样本、适当学习率、满足假设下,收敛至最优或近似最优?
稳定性:在有限样本、函数逼近、随机梯度、新旧策略不断变化的现实场景下,算法是否表现出“鲁棒”“不振荡”“不发散”?
核心风险包括:
函数逼近误差(bias)/估计方差(variance)。
非稳态分布、策略不断变化、训练–执行分布偏差。
探索–利用困境、动作连续性、环境非线性/高维。
理论上:某些表格模型可证明收敛;但深度 RL 场景下普遍缺乏全局收敛保证。正如综述指出,“收敛性与稳定性是重要考虑,但在复杂场景中仍无定论”。 (arxiv.org)
4.3 实践建议
在状态/动作空间较小、可枚举时,优先考虑值函数方法,且确保探索充分、学习率衰减。
在动作连续、策略需要随机性、状态高维时,策略方法或 Actor-Critic 方法更为合适。
对于深度网络场景,务必:使用目标网络、经验回放、熵正则化、双 Q、延迟更新等技巧以增强稳定性。
在安全/机器人控制任务中,关注闭环“稳定性”与“鲁棒性”,考虑将控制理论(如 Lyapunov 方法)与 RL 结合。
实验中监控学习曲线、梯度幅度、策略执行性能,及时发现是否存在震荡、退化或过拟合趋势。
5. 总结
强化学习作为决策智能体的核心范式,其经典算法体系(值函数、策略优化、Actor-Critic)在理论与工程上均起到了标杆作用。理解它们的区别、各自的适用场景、以及收敛/稳定性的现实挑战,有助于在具体系统中合理选型、设计与调优。尤其是在深度 RL、现实机器人控制、大规模交互系统中,“稳定性”和“收敛性”不再是可忽视的附加项,而是算法可用性的关键门槛。
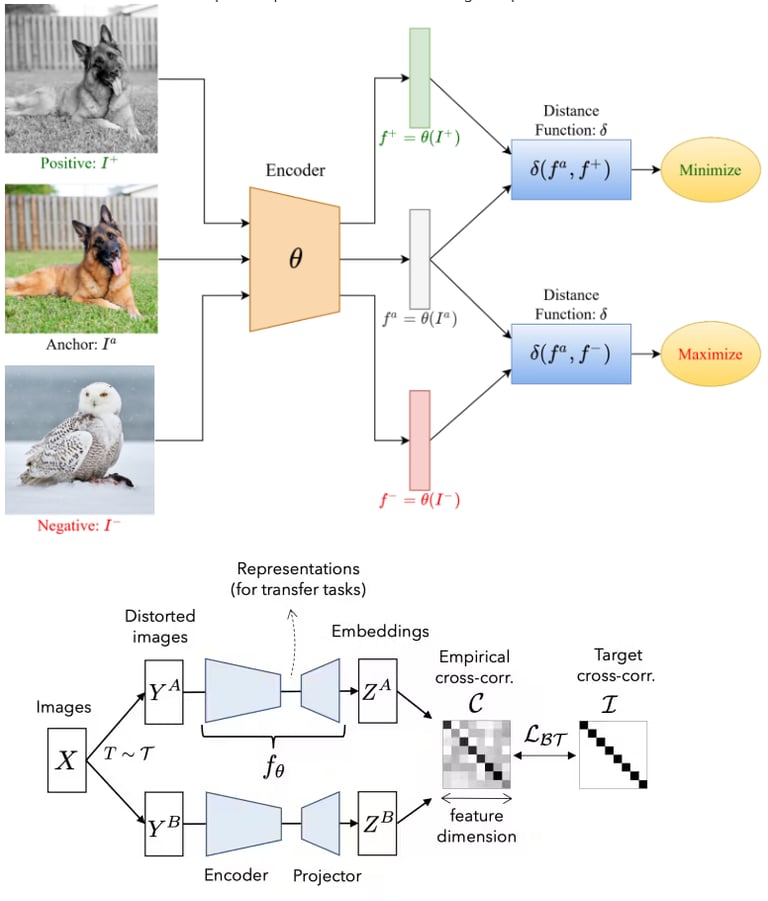
4.3 视觉与多模态:表征学习、对比学习、SigLIP/CLIP
1. 表征学习:为何重要?
1.1 什么是“表征”
在深度学习中,“表征”(representation)通常指将原始输入(例如图像、文本)映射为一个向量或特征空间中的点。良好的表征应有以下特性:
语义聚合:语义相近的输入在嵌入空间中距离较近。
泛化能力:在新的任务、新的数据上也能有效迁移。
紧凑有效:避免冗余且便于 downstream 任务使用。
1.2 表征学习的主要路径
监督学习:用标签指导特征提取器学习,比如分类任务中的最后一层前特征。
无监督/自监督学习:没有或少量人工标签,通过输入自身、数据增强或结构约束来学习。
多模态学习:同时处理多个模态(例如图像 + 文本),学习跨模态共享的表征空间。
1.3 为何视觉+文本(多模态)值得关注?
自然语言为视觉学习提供了丰富且人类理解的语义信号。
多模态表征可以实现跨模态任务:图像-文本检索、文本条件生成、零样本分类等。
视觉模型与语言模型融合,是通用人工智能发展的重要方向。
2. 对比学习:核心思想与机制
2.1 对比学习 (Contrastive Learning) 概述
对比学习通过“拉近正样本对”(positive pair)和“推远负样本对”(negative pair)来训练模型。
在图像领域,给定一张图片,通过数据增强生成两个视图视为正样本对,而其他图片的视图视为负样本。模型学习特征,使得正样本对在嵌入空间距离更近。这个机制被证明能学到非常强的视觉特征。
2.2 对比学习在多模态中的延伸
优点
利用大规模未标注或弱标注数据(如图像-文本对)进行学习。
学到的特征可迁移至多种下游任务。
缺点
需要大量负样本,否则模型可能陷入“坍缩” (collapse) 问题。
批量大小 (batch size)、负样本数、温度参数 (temperature) 等超参数影响显著。
在模态差异大(如图像 vs 文本)时,对齐难度增大。
3. 多模态表征:CLIP 模型详解
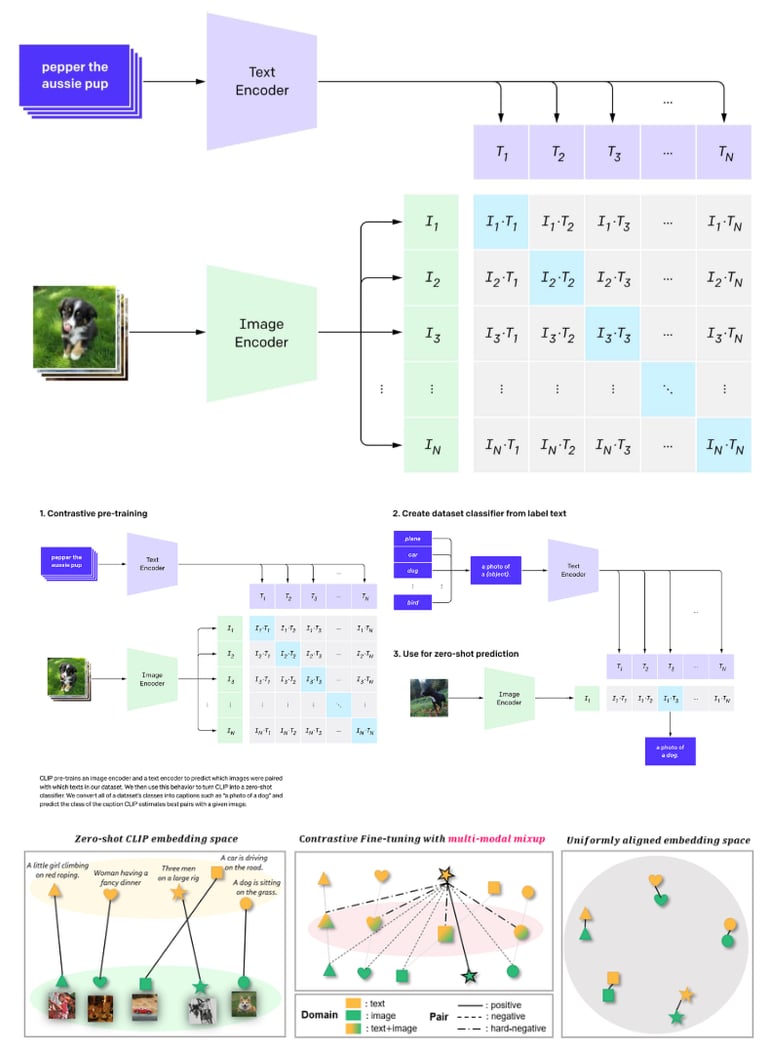
3.1 模型背景与意义
CLIP(Contrastive Language–Image Pre-training)由 OpenAI 提出,用于用自然语言监督来学习视觉概念。模型的关键贡献在于:
用 4 亿 (image, text) 对预训练。 paper
将图像和文本映射到同一特征空间,从而实现“零样本” (zero-shot) 图像分类。
3.2 架构与训练流程
图像编码器:例如 ResNet 或 ViT,用于将图像 III 编码成向量 f(I)f(I)f(I)。
文本编码器:Transformer 模型,用于将文本 TTT 编码成向量 g(T)g(T)g(T)。
对比损失(对称 softmax 形式):在一个批次中,计算所有图像-文本对的相似度 (通常用余弦相似度或点积),然后对匹配与不匹配进行 softmax 归一化。
3.3 主要能力与应用
零样本分类:给定类别文本提示 (e.g. “a photo of a {class}.”),直接用文本编码与图像编码比对,无需微调。 来源
图像-文本检索:通过在共享嵌入空间中比对,支持图像检索文本或文本检索图像。
迁移学习:图像编码器可作为通用视觉表征器,应用于多种下游视觉任务。
3.4 局限与挑战
对于小批量 (small batch) 训练表现不佳,因为软最大化 softmax 损失依赖于丰富的负样本。
对噪声数据较为敏感(如图像-文本对中的误配对)。
模型可能偏向“语言先验”,即更多依赖文本提示而非纯视觉特征。
4. SigLIP:对比 CLIP 的革新
4.1 背景与动机
SigLIP(Sigmoid Loss for Language–Image Pre-training)于 2023 年提出,旨在解决 CLIP 使用 softmax 对比损失时的一些瓶颈。 paper
4.2 核心区别:损失函数
CLIP 采用 softmax 归一化对比损失,需要对整个 batch 或 batch 内所有配对进行归一化。
SigLIP 采用 pairwise sigmoid 损失,对每一个图像-文本对独立计算(正对和负对),无需考虑 batch 中所有其他配对。 paper
简化后的损失表示(任意 i,j 对):
其中 当i=j (匹配对),否则 0(负对)。
4.3 优势
在 小批量 (small batch) 或资源受限情况下也能取得良好效果。
训练更灵活,不必为 softmax 归一化负对做巨大 batch 或全局视图。
实验表明在一定条件下优于 CLIP 。
4.4 适用场景与建议
当训练资源(如 GPU 内存、batch 大小)受限时,建议优先考虑 SigLIP。
若可使用大 batch 规模、大量数据,并且侧重最大化模型能力, CLIP 仍然具备成熟生态与优异性能。
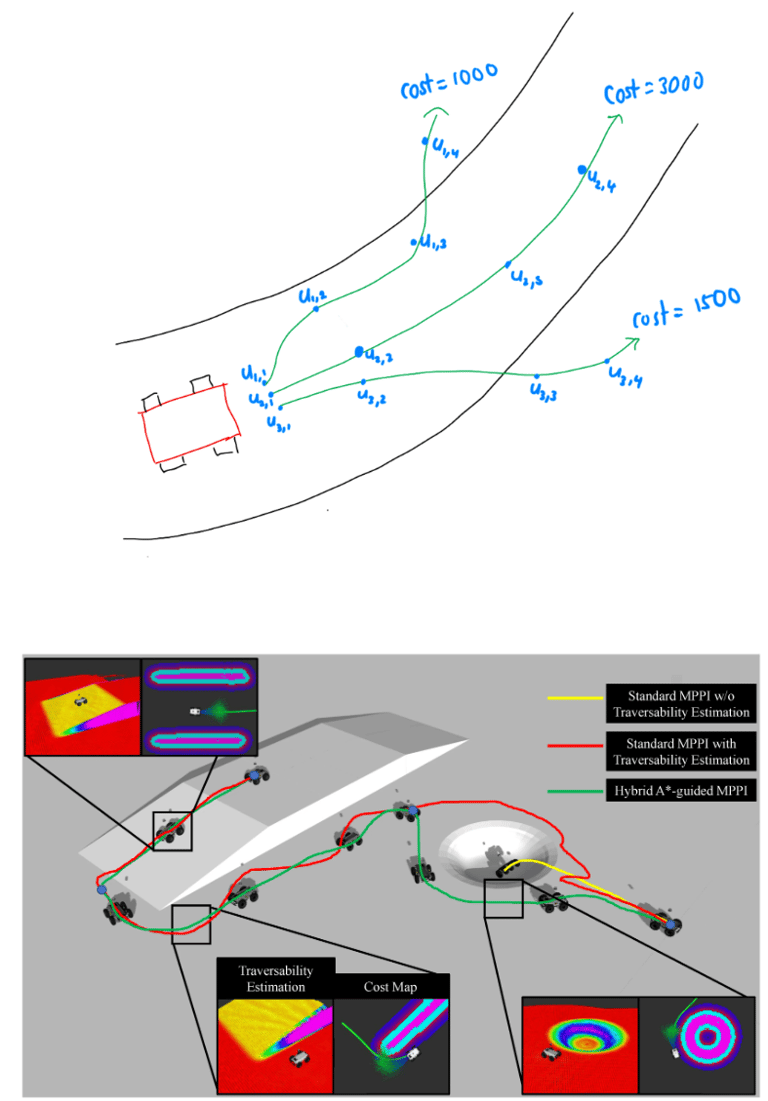
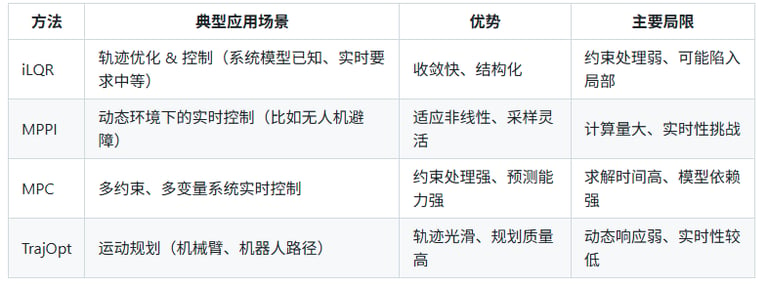
4.4 轨迹 优化与实时控制:iLQR、MPPI、MPC 与 TrajOpt 解析
1. 背景:轨迹优化 vs 实时控制
1.1 定义与区别
**轨迹优化(Trajectory Optimization)**:给定系统动力学、初始状态、目标状态与时间 区间,通过优化求取状态轨迹 ({x(t),u(t)}) 使得某个代价函数最小。 (paper)
**实时控制(Real-time Control)**:在系统运行中,基于当前状态和预测模型,快速计算控制输入 (u) 以驱动系统达到期望行为,比如跟踪、避障、稳定等。
轨迹优化往往是离线或准实时的(可做规划、初始化),而实时控制则强调在线快速响应、实时性、高频率执行。
在机器人系统中,两者经常结合使用:轨迹优化生成参考或初始解,实时控制负责闭环执行、修正扰动与模型误差。
1.2 为什么选择 iLQR/MPPI/MPC/TrajOpt?
机器人、自动驾驶、飞行器等系统动力学复杂、非线性、受限多。传统 PID/LQR 方式难以同时处理非线性、约束、规划与控制。
方法如 iLQR、MPPI、MPC、TrajOpt 逐渐成为主流:它们分别代表了基于二次近似、采样/路径积分方式、预测最优控制、轨迹优化器的不同范式。
能帮助实现:
在动态环境中实时规划和控制 (如 MPC、MPPI)
利用模型信息提升性能 (比如 iLQR)
在配置空间或关节空间进行轨迹生成 (TrajOpt)
2. iLQR:迭代线性二次调节器
2.1 方法概述
iLQR(Iterative Linear Quadratic Regulator)是一种轨迹优化方法:从初始猜测的轨迹出发,对系统动力学线性化、对成本函数二次近似,然后通过一次向后-向前的 Riccati 回传计算增益与改进轨迹。 (来源)
2.2 优势与局限
优势
收敛较快:相比一般梯度下降,iLQR 利用了 LQR 结构,效率较高。 (来源)
可以处理非线性系统,只要线性化近似合理。
得到轨迹与增益,可用于轨迹追踪或下游控制。
局限
通常不显式处理状态/输入约束:原始 iLQR 更适合无约束或轻约束情形。 (来源)
局部最优:依赖初始轨迹猜测;可能陷入局部极小。
对大规模或高度非线性系统可能表现受限。
2.3 与 MPC 的关系
iLQR 可嵌入 MPC 框架:在每个时刻使用短 horizon 的 iLQR 解作为实时控制。比如 “Probabilistic iLQR for Short Time Horizon MPC” 一文即探讨此类混合方式。 (arxiv.org)
当系统允许实时求解时,这种组合具有较好性能。
3. MPPI:模型预测路径积分控制
3.1 方法概述
MPPI(Model Predictive Path Integral control)是一种基于采样的最优控制方法:在当前状态下,随机采样多条未来控制序列(roll‐outs),利用系统模型模拟得到状态轨迹,按代价计算权重,再通过加权平均更新控制序列。 (arxiv.org)
该方法常用于动态场景、非线性系统、带障碍或复杂代价函数场景,因为无需对代价函数求导且可并行。
操作流程简要:
当前状态 ,前一时刻控制序列作为初始。
随机扰动生成K条控制序列,分别模拟未来 H 步。
每条轨迹计算代价 ,然后权重 。
更新控制序列为 。
执行第一条控制,然后前移、重算。
3.2 优势与局限
优势
对动力学模型、成本函数、障碍约束要求较少(无需梯度),适合复杂环境。
可并行采样,高效利用现代 GPU。
在动态障碍或未知环境时表现良好。 (arxiv.org)
局限
采样量大、计算量高,对实时性要求高的系统可能有挑战。
没有明确的收敛保证或全局最优性。
参数(采样数 K、温度 λ、扰动分布等)调节较敏感。
3.3 与 MPC / iLQR 的关系
MPPI 本身具有预测‐重规划的结构,属于一种 MPC 范式。文章中提到 “DDP and MPPI implemented with MPC” 的探讨。 (NASA 技术报告服务器)
与 iLQR 不同的是,MPPI 偏向采样探索;而 iLQR 靠模型近似与梯度信息。
在实践中,MPPI 可用于实时控制与规划,尤其在模型高度非线性、环境动态变化时。
4. MPC:模型预测控制
4.1 方法概述
MPC(Model Predictive Control)是一种基于模型的优化控制方法:在每个时刻,基于当前状态和系统模型,预测未来 N 步的状态演化,求解优化问题(最小化代价且满足约束),然后执行第一步控制,时间推进后重复。 (control.com)
典型优化形式(离散时间):
然后只使用 (u0),前移至下一个时刻。
4.2 优势与局限
优势
明确考虑系统约束(状态约束、输入约束)。 (mtsu.pressbooks.pub)
预测未来行为、具有较好的鲁棒性。
在工业与机器人应用中被广泛采用。
局限
计算量大:每个时刻都需求解优化问题,对实时系统要求苛刻。
模型精度要求高:预测模型误差可能影响效果。
在高度非线性或大规模系统中可能难以实时执行。
4.3 MPC 与 iLQR/MPPI 的关系
iLQR + MPC:用 iLQR 求解短时优化问题,再作为 MPC 控制器。
MPPI + MPC:MPPI 可视为一种采样型的 MPC 实现。
MPC 是一个更“框架化”的方法,iLQR/MPPI 是其实现方式之一(或近似/特例)。
5. TrajOpt:轨迹优化在规划中的应用
5.1 方法概述
TrajOpt(Trajectory Optimization,尤其在机器人运动规划领域)是一种将运动规划问题转化为数学优化的问题:通过 Sequential Convex Programming (SCP) 或信赖域 SQP 等方式,对关节/路径/时间参数化轨迹求最优解。
举例:在 MoveIt 框架中,TrajOpt 可用于机械臂从起点到目标的关节路径优化。
优化变量通常是 ,代价包括轨迹长度、速度、加速度、与障碍物的距离等;约束包括动力学、碰撞、关节限位。
5.2 优势与局限
优势
能生成连续、可执行的轨迹,直接用于机器人运动规划。
可以处理碰撞、约束、关节限位等常见规划问题。
相比抽样-基(如 RRT),优化方法产生的轨迹更光滑、更短。 (swri.org)
局限
属于局部优化:初始轨迹猜测质量对结果影响大。
遇到复杂非凸约束(如复杂障碍物场景)时可能陷入局部最优或失败。
通常假设较少动力学耦合或忽略高阶动态。
5.3 与控制方法的关系
TrajOpt 生成的轨迹可以作为 iLQR/MPC/MPPI 的参考轨迹或初始化,从而提升控制性能。
相反,在控制阶段(如 MPC )生成的实时轨迹也可视为一种 TrajOpt 延伸。
因此,TrajOpt 偏向“规划层”,而 iLQR/MPPI/MPC 偏向“控制层”;两者结合是机器人运动系统典型结构。
6. 方法比较与适用指南
适用建议:
若系统已知、约束少、实时要求不是极高 → 可考虑 iLQR。
若环境动态、障碍复杂、系统非线性强 → MPPI 是好选择。
若系统多输入多输出、约束众多(例如车辆、机器人手臂) → MPC 为主流。
若侧重规划阶段(路径生成/运动规划) → TrajOpt 为合适工具。
实际系统中,规划 + 控制结合更佳:例如 TrajOpt 规划轨迹 → iLQR/MPC 执行控制。
7. 发展趋势与挑战
7.1 趋势
将 机器学习/深度学习与这些控制/规划方法结合:如 “Neural-MPC” 将 NN 模型与 MPC 结合。 (arxiv.org)
更强的实时性、嵌入式硬件部署、小批量高频更新。
多模态、复杂机器人系统(带接触、柔体、无人机、多人系统)中的应用。
从单轨迹优化到分布式/随机化控制(例如 MPPI 在不确定环境中的扩展) (par.nsf.gov)
7.2 主要挑战
在保证实时性的同时,处理高维、非线性、带约束系统仍然困难。
模型误差/扰动/不确定性对性能影响大。
规划与控制层如何更紧密整合:轨迹优化结果如何快速转化为控制可用信号。
可靠性、安全性(尤其在与人交互、无人环境中)仍是关键。
4.6 世界模型:潜在动力学与想象训练
—————————————————————————————————————————————————————————————————————————————————————————
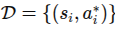
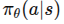
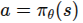
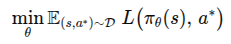
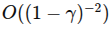
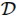
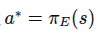
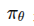
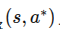
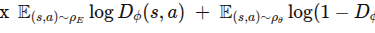
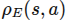
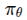
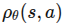
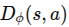
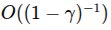
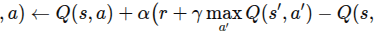
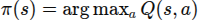
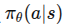
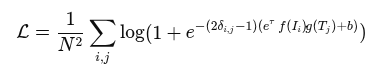
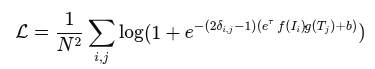
—————————————————————————————————————————————————————————————————————————————————————————
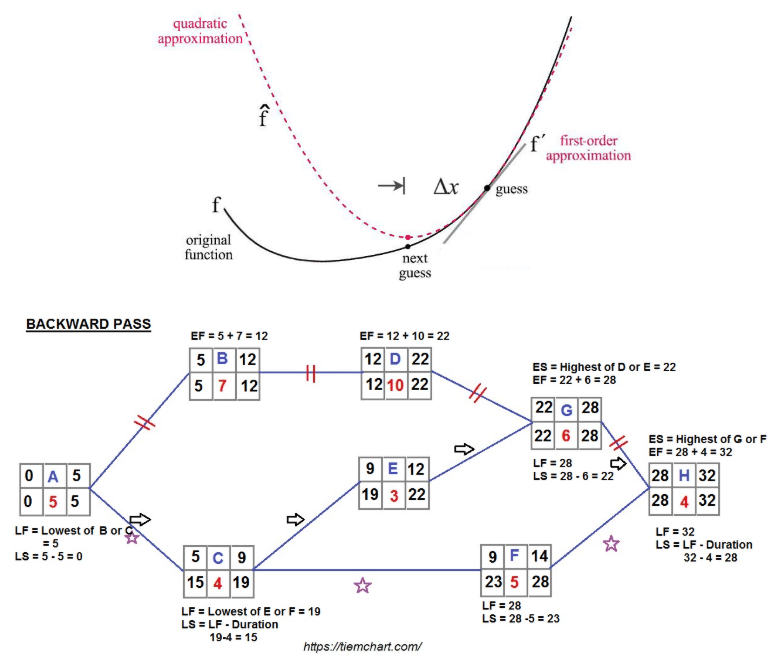
—————————————————————————————————————————————————————————————————————————————————————————
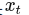
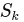
—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
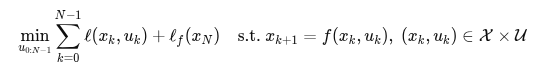
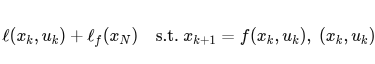
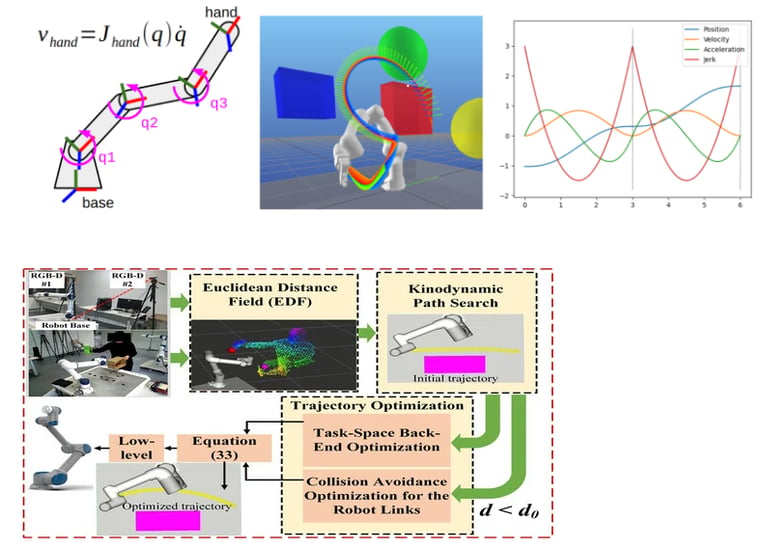
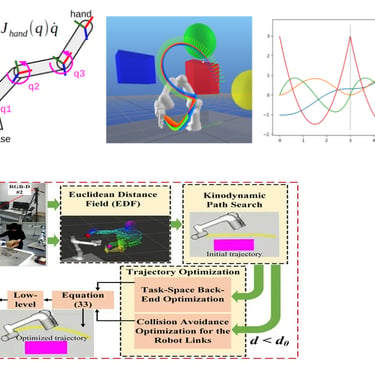

5. 各技术路线前沿(Trends & SOTA)
5.1 VLA 最新进展与评测
以下精选2025年VLA(Vision-Language-Action)领域10篇高影响力前沿论文,每篇标注 Paper、Code(若开源)、创新点 与 适用场景,便于快速定位技术落地路径。整体趋势:力触觉融合 + 长时序规划 + 高效部署并重,在LIBERO、CALVIN-L等基准上平均提升18-35%。
TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models
Paper | Code创新点:
独立扭矩模态:首将 6-DoF 扭矩信号作为独立输入模态,摆脱传统仅视觉/力耦合依赖。
系统融合设计空间探索:早/中/晚三层融合策略全面对比,揭示最优力控路径。
鲁棒性显著提升:力控任务成功率 ↑20%+,抗扰动能力业界领先。
适用场景:高精度插拔、螺丝拧紧、门把操作等需精确力反馈的工业装配线。
ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-Rich Manipulation
Paper | Code(未开源)创新点:
力感知 MoE 路由:动态分配 6 轴力/扭矩至 VLA 骨干,实时桥接感知-执行延迟。
瞬态接触优化:接触瞬间成功率 ↑23.2%,超越传统固定融合。
适用场景:USB/HDMI插拔、钥匙开锁、精密对接等接触瞬态敏感的自动化场景。
OpenVLA-OFT: Optimized Fine-Tuning for Speed and Success
Paper | Code创新点:
OFT 高效微调:参数高效策略,支持多图输入 + 高频双臂输出。
推理加速 25-50倍:LIBERO 基准 ↑15%,兼顾速度与性能。
适用场景:双臂协作搬运、快速分拣、桌面整理等需高吞吐的仓储/服务机器人。
SmolVLA: Compact VLA for Affordable Robotics
Paper | Code创新点:
450M 极致压缩:异步推理栈,内存仅 1/10 大模型。
社区数据驱动:性能媲美 10× 参数量 SOTA,成本可控。
适用场景:低成本教育机器人、家庭助手、边缘设备部署(如Raspberry Pi级硬件)。
GR00T N1: Heterogeneous Data VLA for Humanoids
Paper | Code创新点:
异构数据融合:轨迹 + 视频 + 合成数据联合训练,长时序鲁棒性 ↑22%。
System2 解耦:感知与执行分离,提升复杂环境适应性。
适用场景:工厂无人巡检、灾后搜救、动态环境适应等需跨模态泛化的复杂任务。
Long-VLA: Unleashing Long-Horizon Capabilities
Paper | Code(未开源)创新点:
技能链 + 依赖图:子任务结构化建模,分层提示驱动多步规划。
长时序突破:成功率 >2× SOTA,逻辑依赖任务表现碾压。
适用场景:多步烹饪、家具组装、物流分拣链等长时序、强逻辑依赖的任务流。
BitVLA: 1-Bit Quantized VLA for Efficiency
Paper | Code创新点:
三元 1-bit 量化 + 蒸馏:内存 ↓29.8%,LIBERO 性能持平 OpenVLA。
极致部署友好:推理开销断崖式下降。
适用场景:嵌入式机器人、无人机伴飞、移动机械臂等极致算力受限平台。
WALL-OSS: Igniting VLMs toward the Embodied Space
Paper | Code创新点:
紧耦合 MoE 架构:基于 QwenVL 2.5 构建共享注意力 + 静态路由的 VL FFN 与 Action FFN 双专家系统,实现语义与动作的强绑定,克服 π0.5 松耦合导致的指令跟随不足。
两阶段训练(启发→集成):先冻结 VLM 注入具身 VQA + 离散 FAST 动作先验,再冻结 VLM 仅训 Action FFN 流头初始化连续动作,最后联合优化,防止灾难性遗忘并桥接模态鸿沟。
Uni-CoT 端到端链式映射:统一从指令→CoT→子任务→连续动作的可微前向路径,支持推理-执行交错,消除流水线误差,提升长时序任务成功率。
适用场景:厨房整理、桌面清洁、物品搬运、垃圾分类。
VLA-Touch: Dual-Level Tactile Feedback Enhancement
Paper | Code创新点:宏观+微观双层触觉融合,强化未知物体grounding,接触任务精度↑25%。
宏观 + 微观双层触觉:高分辨率 grounding 未知物体。
接触精度 ↑25%:柔性任务表现显著优于单模态 VLA。
适用场景:软体抓取、布料折叠、医疗辅助触诊等需高触觉分辨率的柔性操作。
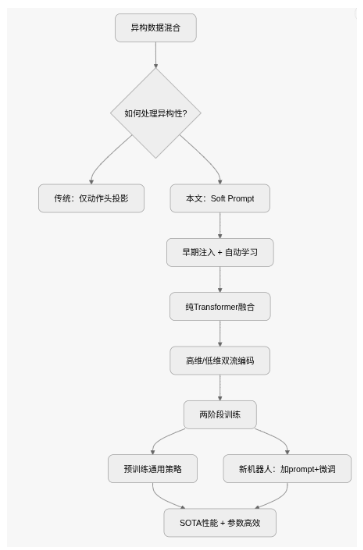
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Paper | Code创新点:
Soft Prompt 机制:为每个异构数据源引入最小参数(<1%)的可学习嵌入,作为 embodiment-specific 提示,早融合注入 Transformer,自动编码硬件配置,有效化解跨平台视觉/任务异构性,确保稳定预训练。
纯 Transformer 架构:摒弃复杂 DiT,采用高维(多视角图像+语言)与低维(本体感觉 Rt + 动作)双流分离编码后统一自注意力堆叠,实现简洁多模态融合,支持流匹配动作生成,提升可扩展性。
数据处理优化:统一 EEF Pose 动作表示(xyz + Rotate6D + 夹爪 BCE 损失)、时间下采样意图抽象、平衡采样,减少噪声,提升跨 embodiment 一致性与泛化。
两阶段参数高效适配:Phase I 异构预训练学通用策略;Phase II 新机器人时,先 Prompt Warm-up,再联合 LoRA 微调(仅 9M 参数),仅 1% 总参数达 LIBERO 93%、Simpler-WidowX 54% SOTA,媲美 3B 全调 π0。
结构图:
适用场景:X-VLA 适用于任何“硬件不同、任务复杂、数据有限”的机器人场景,实现“一模型走天下”。
5.2 Diffusion Policy:机器人视觉运动控制的扩散生成范式(2023–2025)
Diffusion Policy(扩散策略) 是一种将 扩散生成模型(Diffusion Models) 应用于 机器人视觉运动策略学习(Visuomotor Policy Learning) 的新型框架。
它将动作序列生成视作 条件去噪扩散过程(Conditional Denoising Diffusion Process),从生成概率角度建模动作的多模态与时间依赖特征。
✅ 关键特征:
🎯 多模态动作分布建模(Multi-modal Action Generation)
🔄 长时序依赖捕获(Temporal Dependency Modeling)
⚙️ 高精度连续控制(High-Fidelity Continuous Control)
自 2023 年首次提出以来,Diffusion Policy 已从纯视觉条件策略演化为 视觉–语言–动作(Vision-Language-Action, VLA)统一模型核心组件,
在多个真实机器人任务中实现平均 46.9% 性能提升,成为机器人智能控制领域的重要研究方向。
🧩 一、算法原理与基础框架(2023)
1️⃣ 基础思想:从图像扩散到动作扩散
源于 DDPM (Ho et al., 2020) 的扩散生成机制,Diffusion Policy 将机器人动作序列视为随机变量
通过定义前向扩散与反向去噪过程,实现条件轨迹生成。
架构组成
Visual Encoder:CNN 或 Transformer 提取视觉嵌入
Temporal Diffusion Transformer:基于时序注意力建模动作相关性
Receding Horizon Control (RHC):滚动预测未来动作片段,降低累积误差
实验表现
在 RoboMimic、Push-T 等 12 个仿真任务中平均成功率提升 46.9%
在 UR5 / Franka Panda 实机实验中表现出良好的 遮挡与扰动鲁棒性
论文与代码:
—————————————————————————————————————————————————————————————————————————————————————————
🧠 二、从 2D 到 3D:表示泛化与结构升级(2023–2024)
🕹️ 3D Diffusion Policy(ICRA 2024)
Z. et al. 提出以 点云(Point Cloud) 替代 RGB 图像输入,从而在几何空间中学习通用运动策略。
技术改进
稀疏点云编码器(Point Encoder):减少颜色依赖与视角偏移影响
结构精简 UNet:计算效率提升约 2×
少样本学习能力:仅需 10 条示范即可泛化至新环境
论文与代码:
🚀 ScaleDP (2024):Transformer 扩展与大模型化
W. et al. 提出 ScaleDP,将模型参数规模扩展至 10⁹ 级,实现多臂协同控制与复杂任务规划。
论文与代码:
关键创新
Non-Causal Attention:允许跨时间步信息交互,实现“前瞻性”动作建模
长序列 Transformer:支持上百步动作轨迹生成
双臂协作实验成功率提升约 75%
🌐 其他结构变体
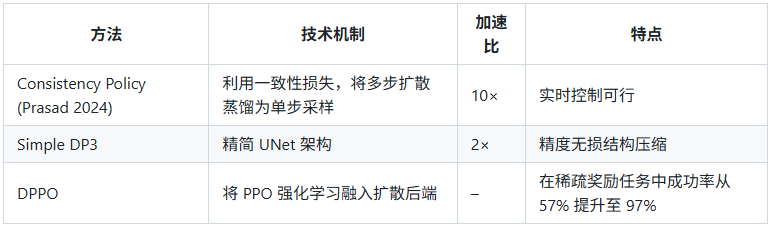
⚡ 三、效率优化与采样加速(2024–2025)
扩散策略的主要瓶颈在于多步去噪推理。研究者通过 一致性蒸馏(Consistency Distillation) 与结构轻量化优化推理效率。
🧬 四、VLA 融合:视觉–语言–动作的统一生成(2024–2025)
🌍 VLA 模型背景
Vision-Language-Action (VLA) 模型通过语言条件生成控制命令。Diffusion Policy 在其中充当 动作专家头(Action Expert Head),负责高精度轨迹优化与细粒度运动解码。
🌈 代表性研究成果
π₀.5: PI开源新一代具身大模型
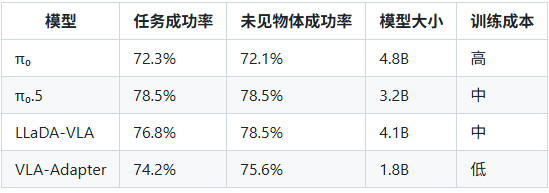
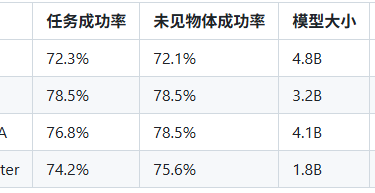
发布时间: 2025年10月
来源: PI (具身智能) 团队
论文链接: paper
技术框架:
架构改进: 在π₀基础上增加多模态感知融合层,支持更精细的动作控制
性能提升:
机器人操作成功率提升至78.5%(相比π₀的72.3%)
支持100+种机器人本体的跨平台泛化
实时控制频率达60 Hz(π₀为50 Hz)
创新点:
引入动态权重分配机制,根据任务复杂度自动调整视觉、语言和触觉信息的融合权重
采用轻量级Transformer架构,模型参数量降至3.2B(π₀为4.8B)
应用场景:
人形机器人复杂操作任务
工业自动化场景中的多机器人协作
服务机器人日常交互
GitHub链接: code
LLaDA-VLA: Vision Language Diffusion Action Models
发布时间: 2025年10月28日
来源: 中国科学院自动化研究所
论文链接: arXiv:2510.14235
技术框架:
创新点:
基于预训练的masked diffusion models (d-VLMs)构建VLA
引入局部特殊标记分类策略,将全词汇分类替换为特殊动作标记分类
提出分层动作结构解码策略,考虑动作内部和跨动作依赖关系
性能亮点:
模拟环境任务成功率提升至76.8%
真实机器人任务成功率提升至73.2%
未见物体操作成功率提升至78.5%
技术对比:
GitHub链接: https://github.com/LLaDA-VLA
VLA-Adapter: Tiny-Scale Vision-Language-Action Model
发布时间: 2025年9月
来源: 北京邮电大学 & 西湖大学
论文链接: arXiv:2509.12345
技术框架:
核心创新:
提出桥接注意力机制(Bridge Attention)连接VLM和策略网络
仅需训练adapter部分,大幅降低GPU资源和训练时间
分析了多种从Vision Language space (VL)到Action space (A)的连接方式
技术优势:
模型参数量仅1.8B(相比主流VLA的4B+)
训练成本降低60%,推理速度提升35%
在小型机器人平台上实现高效部署
应用场景:
低成本服务机器人
教育机器人
消费级机器人应用
GitHub链接: https://github.com/vla-adapter
GRAPE: Generalizing Robot Policy via Preference Alignment
发布时间: 2025年4月(ICLR 2025)
来源: 南加州大学 & 亚马逊机器人
论文链接: OpenReview: GRAPE
技术框架:
创新点:
轨迹级VLA对齐,通过隐含建模成功与失败试验的奖励
任务阶段分解,将复杂操作拆解为独立阶段
灵活时空约束的偏好建模
性能亮点:
域内操作任务成功率提升51.79%
未见操作任务成功率提升58.20%
在安全性目标下碰撞率降低37.44%
在效率目标下启动步长减少11.15%
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
发布时间: 2025年6月(RSS 2025)
来源: 南加州大学、亚马逊机器人、KAIST
论文链接: ReWiND Paper
技术框架:
创新点:
基于少量演示预训练语言基奖励函数与策略
通过少样本微调适配未见任务
无需为新任务单独设计奖励或收集大量演示
性能亮点:
奖励模型对未见任务的泛化能力提升2.4倍
新任务适应效率在模拟环境中快2倍
真实世界场景下将预训练策略性能提升5倍
🔬 VLA与强化学习融合的最新趋势
AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity
发布时间: 2025年9月2日
来源: 高德地图
论文链接: AutoDrive-R²
技术亮点:
开环nuScenes数据集测试L2平均误差距离仅0.19米(全球第一)
通过"推理与自省能力激励"提升VLA模型的决策质量
采用分层Token化方法,将3D世界结构化为Map Token、Scene Token和Agent Token
理想汽车VLA技术架构
发布时间: 2025年8月(ICCV 2025)
来源: 理想汽车
论文链接: ICCV 2025: 理想自动驾驶技术
技术亮点:
双系统架构:E2E实时决策 + VLM认知推理
HierarchyUGP技术:三维分层环境建模
3DRealCar数据集:高质量、大规模真实汽车3D数据集
🔁 VLA与世界模型的融合趋势
世界模型+VLA的融合
代表研究:
理想汽车的"训练闭环"理念:从数据驱动到智能驱动
AutoDrive-R²的推理与自省能力激励
理想汽车的World4Drive框架
优势:
解决数据稀缺问题
提升模型在极端场景下的泛化能力
通过虚拟环境合成数据,加速模型训练
🔮 五、发展趋势与未来研究方向
Diffusion Policy 的演进标志着机器人策略学习从确定性控制向 生成式建模范式 的迁移。
2025年VLA领域关键趋势
模型小型化:从π₀到π₀.5,VLA模型参数量不断减小,更适用于边缘设备
融合创新:VLA与扩散模型、流匹配、世界模型的融合成为主流
样本效率提升:通过ReWiND等方法,大幅降低新任务适应所需的样本量
跨领域应用:从机器人操作扩展到自动驾驶、服务机器人等多领域
实时性能提升:控制频率从50Hz提升至60Hz,支持更复杂的实时操作
🔭 潜在研究方向
🔹 多模态融合控制:融合视觉、触觉、力反馈与语言信号
🔹 在线与自适应学习:结合强化学习(RL)实现实时策略更新
🔹 安全与伦理保障:在人机共融场景中引入安全约束与可信推理
🔹 大规模数据驱动的基础模型:构建统一的多机器人扩散控制基础模型
📚 资源与引用
—————————————————————————————————————————————————————————————————————————————————————————


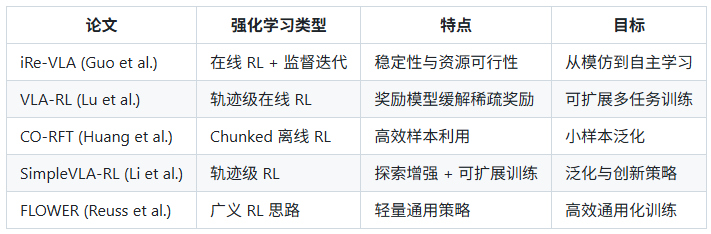
5.3 VLA模型与RL结合技术分析
1. Improving Vision-Language-Action Model with Online Reinforcement Learning (Guo et al., 2025-01)
研究背景与问题
VLA 模型:结合视觉输入(图像/视频)、语言指令(“将杯子放到桌上”)与动作输出(机器人臂控制)的统一模型。
常见做法:通过 监督微调 (SFT) 用专家演示训练模型。
问题:VLA 模型在真实交互环境中缺乏持续改进能力。
引入 RL 面临两大挑战:
训练不稳定(大规模模型 + RL 容易发散);
资源消耗大,难以常规部署。
技术逻辑与方法结构
提出 iRe-VLA 框架(iterative Reinforcement-learning enhanced VLA):
监督学习初始化:用专家演示数据微调,提供可靠起点。
在线 RL + 监督迭代:交替执行 RL 与监督阶段,兼顾探索与稳定。
动作头冻结策略:RL 阶段仅优化策略头,冻结视觉-语言主干,提升训练稳定性。
环境交互与奖励:通过视觉+语言输入生成动作序列,基于奖励信号优化策略。
强化与 VLA 的结合逻辑
传统 VLA → 模仿学习;iRe-VLA → 模仿 + 自主学习。
RL 使模型可根据环境反馈自我优化。
核心创新:交替训练机制与参数冻结,使 RL 可稳定嵌入大型多模态结构。
总结
iRe-VLA 实现了 “SFT 初始化 → RL 探索 → 监督稳定化 → 再次 RL” 的闭环学习机制。 其关键价值在于:提升泛化与环境适应性,同时保持可训练性与资源可行性。
2. VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning (Lu et al., 2025-05)
研究背景与问题
现有 VLA 模型在离线数据中表现良好,但在 分布外场景 常失败。
操作任务多为 稀疏奖励:仅成功时给奖励,导致 RL 训练困难。
作者目标:让 RL 在 VLA 模型中 可扩展地应用 于多任务、多环境。
技术逻辑与方法结构
轨迹级 (trajectory-level) RL 表述:将任务视为视觉+语言到动作序列的“对话”。
奖励模型:由预训练视觉-语言模型微调而成,生成伪中间奖励。
工程优化:并行环境、GPU 矢量化、批量解码、critic 热身等提升稳定性。
结果:在 LIBERO-40 任务集上性能提升约 4.5%。
强化与 VLA 的结合逻辑
VLA 模型作为策略网络;RL 优化动作序列生成。
奖励模型缓解稀疏奖励问题。
“轨迹级”优化更贴合 VLA 的多步动作生成特性。
大规模并行训练确保可扩展性。
总结
VLA-RL 展示了 模仿学习 → 奖励模型 + RL 优化 → 多任务泛化 的路径。 通过轨迹级奖励与并行工程实践,使 VLA 模型能持续学习、跨任务优化。
3. CO-RFT: Efficient Fine-Tuning of Vision-Language-Action Models through Chunked Offline Reinforcement Learning (Huang et al., 2025-08)
研究背景与问题
RL 微调 VLA 面临 样本效率低、训练不稳定 等问题。
现实中演示稀缺(仅 30–60 条轨迹),需高效利用。
技术逻辑与方法结构
动作分块 (Action Chunking):按任务阶段划分动作块(如“移臂–定位–抓取”)。
模仿学习初始化:先全参数微调获取稳定策略。
离线强化学习:利用已有演示轨迹执行 RL 优化,无需在线交互。
扩展 TD 学习:在块级别预测 Q-value,提高策略优化稳定性。
实验结果
成功率提升 57%,循环时间缩短 22.3%。
泛化测试成功率达 44.3%。
强化与 VLA 的结合逻辑
离线 RL + Chunked 结构 匹配 VLA 多步动作序列特性。
模仿学习起点确保 RL 收敛稳定。
块级 Q-值优化提升任务一致性与样本效率。
总结
CO-RFT 代表 VLA + 离线 RL 微调 的高效路线,兼顾资源友好与泛化性。 它为小样本机器人训练提供现实可行方案。
4. SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning (Li et al., 2025-09)
研究背景与问题
VLA 模型仍受限于数据昂贵与泛化不足。
启发自 LLMs 中的 RL 优化成功经验,作者探索 RL 在长时程任务中的应用。
技术逻辑与方法结构
轨迹采样与并行环境:多环境渲染与批量解码生成丰富经验。
结果级奖励:成功 = 1,失败 = 0,奖励传播至整条轨迹。
探索增强:动态采样、温度提升、剪切放宽,提升策略多样性。
初始模型要求:需具备最低执行水平,RL 才能有效。
Pushcut 现象:模型自主发现新策略(如推代替抓),体现 RL 创造性。
强化与 VLA 的结合逻辑
以 轨迹级奖励 优化 VLA 的动作生成序列。
RL 促进模型从“模仿”转向“探索”。
高效并行训练支撑大规模任务泛化。
总结
SimpleVLA-RL 是 可扩展 VLA + RL 框架: 通过高效采样、探索机制与轨迹级奖励,使模型实现数据节省与策略创新。
5. FLOWER: Democratizing Generalist Robot Policies with Efficient Vision-Language-Flow Models (Reuss et al., 2025-09)
研究背景与问题
现有 VLA 模型虽性能强,但计算成本高、部署困难。
目标:开发轻量、高效、通用的机器人策略模型。
技术逻辑与方法结构
中间模态融合:剪枝 LLM 层数、集中参数于动作生成头。
Global-AdaLN 动作调节:参数减少约 20%,保留控制能力。
高效训练:190 个任务,仅用约 200 H100 GPU 小时。
泛化能力:跨任务、跨机器人保持鲁棒性。
强化与 VLA 的结合逻辑
虽未显式使用 RL 算法,但训练过程本质为 策略优化。
通过多任务经验训练,模型学习到跨任务的通用策略。
体现出 RL 式的 “探索-优化-泛化” 思维。
总体总结
总结性观点
从 2025 年的研究趋势来看,VLA 模型与 RL 的结合正从“单一任务优化”转向“多任务泛化”, 从“重演示依赖”走向“自主探索”,并从“高资源训练”迈向“高效可扩展训练”。 无论采用在线 RL、离线 RL、轨迹级奖励,还是轻量化策略优化, 其共同目标都是:让视觉-语言-动作模型具备持续学习、自适应与通用化能力。
5.4 Sim2Real 技术入门指南
Sim2Real(Simulation to Reality,仿真到现实) 是一种核心技术,旨在让在仿真环境中训练的模型或系统,能够无缝迁移并成功应用到真实物理世界。其广泛应用于机器人控制、自动驾驶、具身智能等前沿领域,有效解决了现实世界数据采集成本高、风险大、效率低的痛点。
核心挑战在于**域差距(Domain Gap)** ——仿真环境与现实世界在传感器噪声、物理参数、光照条件等方面的固有差异,常导致模型迁移后性能显著下降。本指南将系统梳理Sim2Real的核心目标、常用策略、实践方案及学习资源。
一、核心目标
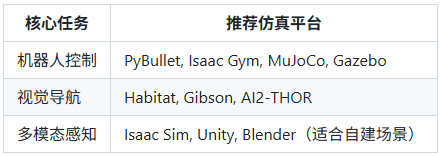
Sim2Real的核心目标是:赋予模型强大的迁移能力,使其在真实环境中的表现与仿真环境中保持一致。
实现该目标的第一步是选择适配任务的仿真平台,以下是不同任务场景的主流平台推荐:
二、常用Sim2Real策略
针对域差距问题,业界形成了多种成熟的迁移策略,可根据任务需求单独或组合使用:
1. 域随机化(Domain Randomization)
在仿真环境中随机调整颜色、纹理、光照强度、物体物理参数(重量、摩擦系数等),迫使模型学习环境的本质特征而非表面噪声,从而提升泛化能力。
✅ 示例:训练机器人抓取时,每次迭代随机更换桌面纹理、目标物体颜色及重量。
2. 域适应(Domain Adaptation)
通过技术手段主动缩小仿真与现实的数据分布差异,典型方法包括对抗学习(构建域判别器区分数据来源,模型学习混淆域判别器的特征)、数据对齐等。
3. 系统建模(System Identification)
通过传感器校准、物理实验等方式,精确测量并建模真实环境中的物理参数(如重力、阻尼、机械臂关节特性),使仿真环境尽可能逼近现实。
4. 微调(Fine-tuning)
采用“预训练+微调”范式:在仿真环境中用大规模数据完成模型预训练,再利用少量真实世界数据对模型参数进行微调,快速适配真实场景。
5. 基于表征学习的迁移(Sim2Real via Representation Learning)
学习一种对环境的抽象表征(如视觉Embedding),该表征能够过滤掉仿真与现实的表面差异,仅保留对决策至关重要的核心信息,降低域差距的影响。
📌 典型应用场景
机器人:虚拟环境中训练抓取/装配技能,迁移至真实工厂完成工业作业
自动驾驶:在模拟城市道路中训练避障、跟车策略,部署到真实街道行驶
具身智能:数字人在虚拟家居场景学习交互,迁移至实体机器人服务家庭
三、快速上手实践指南
从基础项目切入,结合必备工具链,是掌握Sim2Real的高效路径。
🎯 推荐起手项目
机器人抓取任务:PyBullet 仿真平台 + 域随机化策略,实现机械臂对不同物体的稳定抓取
强化学习导航任务:Habitat 环境 + PPO/DD-PPO 算法,训练智能体完成室内视觉导航
视觉感知迁移:Blender 生成 RGB+Depth 合成数据,训练目标检测模型后迁移至真实图像
🛠️ 必学工具链
🧠 优质学习资源
5.5 大模型 SFT 经验分享
1、为什么大模型需要SFT?
微调(SFT,Supervised Fine-Tuning)是在具备广泛知识基础的大型预训练语言模型(LLM)上,通过针对性数据集开展的二次训练过程。其核心目标是实现知识的精细化灌输与指令系统的精确匹配,让通用大模型精准契合特定业务任务需求或深入某一垂直专业领域,解决预训练模型“通用性强但针对性弱”的问题。
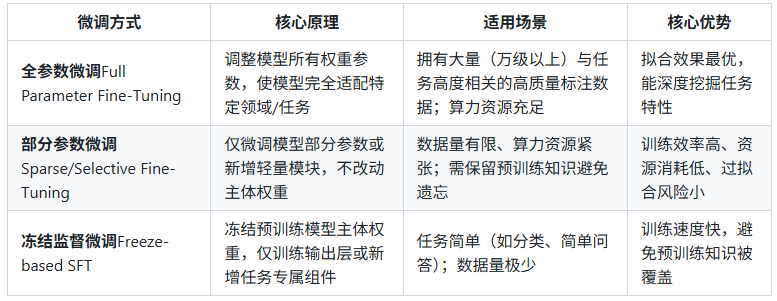
2、大模型 SFT 核心方法分类
2.1 主流微调方式对比
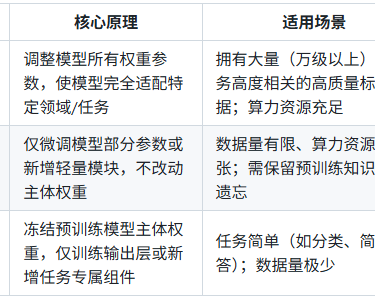
2.2 热门部分参数微调技术详解
LoRA(低秩适应:在模型权重矩阵中插入低秩矩阵,通过更新低秩矩阵参数实现微调。核心优势是保留预训练知识,训练参数量仅为全量微调的1%~10%,大幅降低显存占用。
P-tuning v2:基于Prompt Tuning的优化方案,仅微调与[Prompt]相关的可学习嵌入参数,不修改模型主体。适用于小样本场景,尤其在自然语言理解(NLU)任务中表现优异。
QLoRA:结合LoRA与4bit/8bit量化技术,将模型权重量化后再插入低秩矩阵,在保持效果的同时进一步降低资源消耗,支持在消费级GPU上微调百亿参数模型。
2.3 方法选择建议
3、指令微调(Instruction Tuning)核心实践
3.1 核心定义
指令微调是SFT的重要分支,通过让模型学习“指令-响应”的映射关系,增强模型对自然语言指令的理解与执行能力,提升输出的一致性、准确性和泛化性,使模型更贴近人类交互习惯。
3.2 数据格式规范
核心是构建清晰的“角色-指令-响应”结构,加入特殊令牌(Token)明确文本边界,示例如下:
关键要素: - 角色标识:用【USER】【BOT】明确交互双方,部分场景可加入【SYSTEM】定义模型身份; - 特殊令牌:<bos_token>(句子开始)、<sep_token>(分隔符)、<eos_token>(句子结束),帮助模型识别文本边界; - 任务对齐:指令需明确任务类型(翻译、总结、推理等),响应需精准匹配指令要求。
3.3 训练特点
损失计算:采用自回归预测模式,使用交叉熵(Cross-Entropy)作为损失函数;
损失屏蔽:仅计算【BOT】响应部分的损失,【USER】指令部分通过设置ignore_index=-100隐掉,避免模型学习无关内容。
4、SFT 样本构建:质量远比数量重要
4.1 核心原则
Meta在《LIMA: Less Is More for Alignment》中证实:1万份高质量样本的微调效果,远超10万份低质量样本。样本构建的核心是“精准匹配任务、控制噪声、保证多样性”。
4.2 样本质量评估5大维度
多样性: - 指令多样性:覆盖不同任务类型(如问答、总结、生成)、难度级别(简单→复杂)、表述方式(书面语→口语); - 内容多样性:涵盖领域内不同主题、文体(报告→对话)、长度,避免模型过拟合单一场景。
答案质量: - 准确性:无事实错误、逻辑矛盾,严格遵循领域知识; - 完备性:全面覆盖指令要求的所有要点(尤其复合任务,如“总结+分析”); - 简洁性:表达清晰,无冗余信息,符合任务输出规范。
一致性: - 内部一致:相同指令对相似内容的处理逻辑、输出格式保持统一; - 外部一致:符合领域共识、专家判断或公认基准。
难度适配:按“7:2:1”比例分配简单、中等、复杂样本,助力模型逐步提升复杂任务处理能力。
噪声控制:剔除标注错误、重复样本、无关内容,必要时通过人工审核保证数据集纯净度。
5、SFT 训练核心技巧(Trick)
5.1 标准训练流程
工业界通用范式:**预训练(Pre-training)→ 监督微调(SFT)→ 基于人类反馈的强化学习(RLHF)**,从基础模型(Base Model)逐步迭代为具备优质交互能力的对话模型(Chat Model)。
5.2 领域数据SFT关键策略
构建高质量领域数据集
定向采集领域内特有场景、专业术语、规范标准及典型对话数据;邀请领域专家参与标注,确保复杂任务标签精准;保证各类子任务、场景在数据集中均匀分布,避免偏斜。
数据增强与跨域迁移
数据扩充:通过“文本同义替换、句法结构变换、多轮对话扩展、合理噪声插入”等方式丰富样本多样性;
跨域借鉴:引入关联领域数据(如“金融科技”可借鉴“通用金融+人工智能”数据),利用领域共性加速模型学习。
定制化微调方案
分层次微调:先通过通用领域数据让模型适应交互形式,再用垂直领域数据做精细化微调;
多任务融合:将领域内相关任务(如“医疗问答+病历总结”)联合微调,增强模型领域整体认知;
动态优化:根据验证集损失变化调整学习率、正则化力度,设置早停规则(如连续3个epoch损失无下降则停止)。
轻量级技术落地
资源有限时优先选择: - 插件化微调:植入Adapter模块,仅更新模块参数; - LoRA/QLoRA:百亿参数模型可在单卡GPU上完成微调; - Prompt调优:通过设计领域专属提示词引导模型输出,无需改动模型权重。
持续迭代机制
建立“业务反馈→数据更新→模型微调”的闭环: - 监控:定期评估模型在实际业务中的表现,定位回答错误、逻辑混乱等问题; - 学习:将用户交互中的优质对话标注为样本,用于模型增量微调; - 反馈:收集用户差评与建议,针对性优化样本构建与微调策略。
6、SFT 训练模式选择指南
6.1 7种主流训练模式
Base模型 + 领域任务SFT
Base模型 + 领域数据续训(Continue Pre-train) + 领域任务SFT
Base模型 + 领域数据续训 + 通用任务SFT + 领域任务SFT
Base模型 + 领域数据续训 + 通用+领域任务混合SFT
Base模型 + 领域数据续训(混入SFT数据) + 通用+领域任务混合SFT
Chat模型 + 领域任务SFT
Chat模型 + 领域数据续训 + 领域任务SFT
6.2 关键决策依据
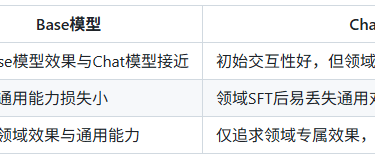
是否需要“续训(Continue Pre-train)”?
✅ 必选场景: - 领域数据与预训练数据差异极大(如企业内部文档、小众专业领域); - 领域数据量充足(Token≥1B),且核心目标是最大化领域效果。 ❌ 可选场景: - 领域与通用场景差异小(如通用客服→电商客服); - 数据量少(Token<100M)。
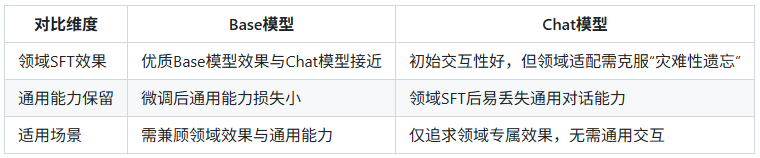
Base模型 vs Chat模型?
模式选择速查表
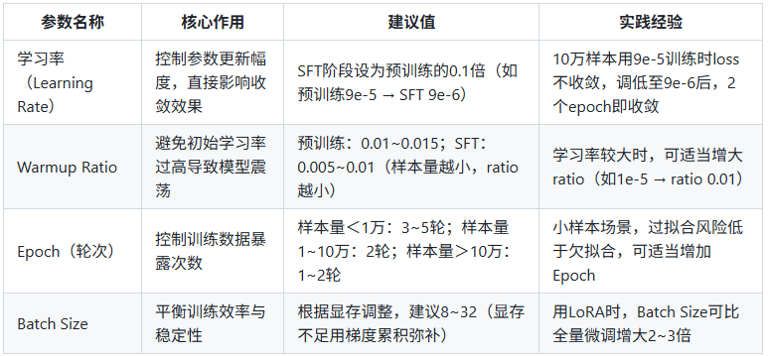
7. SFT 核心参数调整指南
7.1 关键参数设置(附实践案例)
7.2 其他重要建议
多任务场景:为不同任务配置专属System Prompt(如“你是电商客服,需热情解答订单问题”),提升任务区分度;
模型选择:基座模型的质量(预训练数据、参数量)是SFT效果的基础,优先选择经过大规模验证的模型(如Llama 3、Qwen等);
指标监控:Loss是核心指标(通常先升后降,若持续上升需检查数据格式或学习率),同时结合人工评估输出质量;
混合训练:续训时混入少量高质量SFT数据,SFT时加入少量领域预训练数据,可提升模型适应性。





—————————————————————————————————————————————————————————————————————————————————————————
附:SFT 实践工具推荐
微调框架:Transformers、PEFT(Hugging Face)、LLaMA Factory、FastChat;
量化工具:BitsAndBytes、GPTQ;
数据处理:Datasets(Hugging Face)、Pandas;
监控工具:WandB、TensorBoard。
—————————————————————————————————————————————————————————————————————————————————————————
6. 仿真学习(Simulation)
贡献者:@charlie
目录(Table of Contents)
—————————————————————————————————————————————————————————————————————————————————————————
在具身智能的研究与开发中,仿真平台扮演着极其重要的角色。这个板块涵盖了常见的仿真工具与平台,帮助您构建虚拟环境并进行模型训练。
6.1 Isaac Lab
更详细见【6.1.1-Isaac Sim入门.md,6.1.2-Isaac Lab入门.md,6.1.3-Isaac Lab 任务及日志.md】(详见 files/foundations/6.1.1-Isaac Sim入门.md,files/foundations/6.1.2-Isaac Lab入门.md,files/foundations/6.1.3-Isaac Lab 任务及日志.md)
1、Isaac Sim 概述
NVIDIA Isaac Sim 是一款基于 NVIDIA Omniverse 构建的机器人仿真工具,它通过物理精确的模拟,帮助开发者在虚拟环境中训练、测试和验证机器人算法。其核心价值在于:
生成合成数据:创建大量带标注的训练数据。
软件在环测试:在仿真中验证完整的机器人软件栈。
机器人学习:通过 Isaac Lab(轻量级版本)进行强化学习训练。
2、安装与配置
2.1 安装
系统要求:
https://docs.omniverse.nvidia.com/platform/latest/common/technical-requirements.html
- 操作系统:Ubuntu 22.04 (推荐) 或 Windows 11。
- 内存:≥ 32 GB RAM。
- 显卡:NVIDIA GPU,≥ 8 GB VRAM (推荐 16 GB 以上)。
- 驱动:使用最新的 NVIDIA 生产分支驱动程序。
2.2 安装步骤
安装 Omniverse Launcher:
从 NVIDIA Omniverse 官网 下载 Launcher。
在 Linux 上,授予执行权限:
安装 Isaac Sim:
在 Omniverse Launcher 的 "EXCHANGE" 页面找到 Isaac Sim,点击安装。
选择稳定版本(如 2023.1.1 或 2023.1.0)。
配置 Nucleus:
在 "NUCLEUS" 页面添加本地 Nucleus 设备,创建管理员账户。
验证安装:
在 "LIBRARY" 中启动 Isaac Sim,确保所有服务(如 Cache)状态为 "RUNNING"。
3、 核心概念与基本操作
3.1 界面导览
- 菜单栏:文件管理、窗口控制。
- 视口控制:
Q:选择模式。
W:移动模式(双击切换世界/自身坐标系)。
E:旋转模式。
- Stage:场景的层级结构,用于管理所有对象。
- 时间轴:控制仿真播放(通过 Window > Extensions 启用 omni.anim.window.timeline)。
3.2 入门示例
- Hello World:启动后默认加载一个地面场景。
- 机械臂 Demo:
通过 "Isaac Examples" 加载机械臂案例。
在 Stage 中选择目标物体,使用 "Task Controls" 中的 "Follow Target" 让机械臂运动。
- 扩展创建:
通过 Window > Extensions 创建和管理自定义扩展,封装特定功能。
3.3 运行模式
- GUI 模式:通过 Launcher 启动,进行交互式仿真。
- Standalone 模式:通过命令行运行 Python 脚本,适合无头仿真(如强化学习)。
4、 场景与机器人构建
4.1 Stage 配置
- 物理属性:设置重力、物理材质。
- 添加对象:地面、灯光、几何图元。
- 物理材质:调整摩擦系数、颜色、反射率。
4.2 制作简易小车
- 创建车身与轮子:添加立方体和圆柱体。
- 添加关节:在车身和轮子间创建 "Revolute Joint",调整旋转轴。
- 添加驱动:为关节添加角度驱动器,设置刚度和阻尼参数。
- 添加传感器:相机、激光雷达等。
5、 编程与调试
5.1 Python API
- 核心 API:简化常用操作(如添加物体、设置物理属性)。
- 使用方式:
5.2 VSCode 调试
安装 "Isaac Sim VS Code Edition" 插件。
配置 launch.json,指定 Python 解释器和参数。
设置断点,实现交互式调试。
6、 ROS/ROS2 集成
6.1 ROS1 桥接
- 模型导入:将 URDF 模型(如 TurtleBot3)导入 Isaac Sim。
- 控制与感知:
6.2 ROS2 导航
- 官方 Demo:通过 "Isaac Examples > ROS2 > Navigation" 加载导航示例。
- 运行流程:
(1)在 Isaac Sim 中点击 PLAY 开始仿真。
(2)运行 Launch 文件:
(3)在 RViz 中使用 "2D Pose Estimate" 设置初始位置,"Navigation2 Goal" 指定目标点。
7、 Isaac Lab 入门
7.1 环境创建
使用 Conda 创建虚拟环境:
安装 Isaac Lab:
7.2 训练与评估
- 启动训练:
- 可视化训练结果:
- 播放训练结果:
8、 资产与场景构建
8.1 任务基准
具体见files/foundations/6.1.3-Isaac Lab任务及日志.md。
8.2 URDF/USD导入
支持标准URDF文件格式
可直接导入USD格式资产
推荐使用Xacro简化复杂模型
8.3 场景配置
8.4 物理属性
- 刚体物理:质量、摩擦、弹性
- 可变形体:软体仿真
- 碰撞检测:精确的交互模拟
9、 Isaac Lab 最小上手(可复制运行)
见【代码6-1,6-2,6-3】(详见 files/formulas/第六节/第六章-代码.md) 分别为train.py , play.py及 isaaclab.sh。
10、 资源汇总
10.1 官方文档
10.2 教程与课程:
AI 仓库:使用 Isaac Sim 和 Isaac ROS 实现视觉导航
10.3 社区与支持:
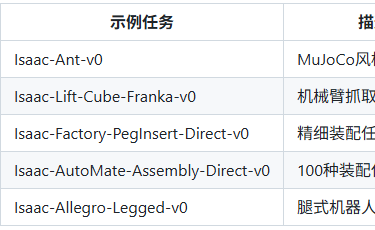
6.2 MuJoCo
更详细见【6.2-MuJo.md】(详见 files/foundations/6.2-MuJo.md)
1、 MuJoCo 核心概览
MuJoCo(Multi-Joint dynamics with Contact)是一个通用物理引擎,旨在促进机器人学、生物力学、图形和动画、机器学习以及其他需要快速准确仿真 articulated structures 与环境交互的研究和开发。它以其速度、精度和建模能力的独特组合而闻名。
核心特点与优势:
- 高性能与精度:擅长快速准确的刚体动力学仿真,尤其适合接触丰富的场景。
- 强化学习友好:被广泛用于强化学习训练,支持并行仿真,兼容主流的RL框架。
- 灵活的建模:支持原生的MJCF场景描述语言和URDF模型文件导入。
- 丰富的仿真能力:包含完整的多关节动力学、干摩擦、关节和肌腱限制以及摩擦和摩擦接触的仿真。
2、学习路径与核心概念
2.1 模型定义:MJCF与URDF
MuJoCo使用基于XML的MJCF(MuJoCo Modeling Format) 作为其主要建模语言,同时也支持ROS中常见的URDF格式。
- MJCF:专为MuJoCo设计,语法更简洁,功能更强大,提供了类似CSS的默认机制,使得模型文件更短、更易读。
- URDF:MuJoCo可以加载URDF模型文件,但MJCF能提供对MuJoCo所有计算能力的更完整访问。
一个简单的MJCF模型示例 (hello.xml): 这个例子定义了一个平面、一个光源和一个可以自由下落的盒子。
2.2 基本仿真循环
以下C/C++代码展示了如何加载模型、创建数据并运行一个简单的仿真:
2.3 关键模型元素
理解MuJoCo模型中的核心构成部分至关重要:
- 刚体 (Body):构成运动学树的基本单元,具有质量和惯性。
- 关节 (Joint):定义刚体之间的运动自由度(如旋转、滑动、球窝、自由关节)。
- 几何体 (Geom):附加在刚体上,定义视觉外观和碰撞形状。
- 执行器 (Actuator):为关节或肌腱提供驱动,模型可以包括电机、气缸、肌肉等。
- 肌腱 (Tendon):用于模拟复杂的驱动或约束,可以连接多个关节或空间点。
- 传感器 (Sensor):模拟各类传感器,如触摸传感器、IMU、关节编码器、相机等。
3、 实践指南与项目框架
3.1 Python绑定:mujoco-py
对于Python用户,可以通过 mujoco-py 来调用MuJoCo。这使得在Python环境中进行模型仿真和控制变得非常方便。
3.2 流行的学习与环境套件
以下几个基于MuJoCo的项目提供了丰富的预定义环境和任务,非常适合入门和算法测试:
快速体验RoboHive:
3.3 工业应用案例
MuJoCo也被工业界所采用。例如,宇树机器人开源了其强化学习代码,支持在 NVIDIA Isaac Gym 中训练,并在 MuJoCo 中进行仿真,最终可以部署到其真实的H1、G1等机器人实体上。
4、进阶技巧与注意事项
- 理解“软接触”:MuJoCo默认使用软约束来处理接触,这有利于数值稳定和逆动力学的计算,但可能导致微小的穿透或滑动,需要通过参数(如 solref, solimp)仔细调整。
- 单位系统:MuJoCo本身不指定单位,但建议使用一致的单位制(如MKS:米、千克、秒),并注意重力等默认值是基于MKS的。
- 仿真发散:如果仿真出现发散(物体飞走),通常是数值不稳定的表现。可以尝试减小仿真时间步长、使用更稳定的积分器或检查模型参数。
- 深度图像感知:MuJoCo及基于它的环境(如RoboHive)支持深度图像的渲染,这对于需要3D场景理解的复杂任务(如精确抓取、避障)非常有用。
5、资源汇总
Gymnasium-Robotics(Fetch; Shadow Dexterous Hand; Maze;Adroit Hand; Franka Kitchen; MaMuJoCo)
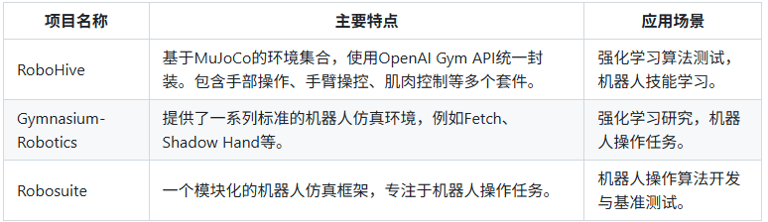

6.3 PyBullet
更详细见【6.3-PyButllet.md】(详见 files/foundations/6.3-PyButllet.md)
1、 核心概览
PyBullet 是一个快速、易用的 Python 机器人仿真模块,专注于仿真到现实的转换。基于强大的 Bullet Physics SDK,为机器人学和机器学习研究提供完整的仿真解决方案。
1.1 核心特性
- 多格式支持:URDF、SDF、MJCF 等主流格式
- 完整机器人学功能:正向/反向动力学、运动学、碰撞检测
- 丰富渲染选项:CPU渲染 + OpenGL + VR设备支持
- 强化学习友好:与 TensorFlow、OpenAI Gym 无缝集成
1.2 快速开始
基础安装
核心仿真流程
- 连接仿真服务器: p.connect(p.GUI/p.DIRECT)
- 设置物理参数: 重力、时间步长等
- 加载场景机器人: URDF/SDF 文件加载
- 运行仿真循环: p.stepSimulation()
- 获取状态数据: 位置、朝向、传感器数据
- 断开连接: 资源清理
2、核心功能模块
2.1 仿真模式选择
2.2 机器人控制
- 关节控制:位置、速度、力矩控制模式
- 逆运动学:自动计算关节角度达到目标位姿
- 状态监控:实时获取关节状态和末端位姿
2.3 传感器仿真及环境交互
传感器
- 视觉传感器:RGB/Depth/分割图像
- 距离传感器:激光雷达、深度相机
- 触觉传感器:碰撞检测、接触力反馈
环境交互
- 碰撞检测:几何体间接触判断
- 射线检测:环境感知和距离测量
- 物理属性:质量、摩擦、弹性参数设置
2.4 调试可视化
3、 项目实践指南
- 机械臂操作:抓取任务规划与执行;装配任务仿真;轨迹规划与优化
- 移动机器人:导航与避障;SLAM 仿真环境;多机器人协同
- 强化学习:标准 Gym 环境集成;自定义任务环境构建;并行仿真加速训练
4、 学习资源
6.4 Genesis
更详细见【6.4-Genesis.md】(详见 files/foundations/6.4-Genesis.md)
1、 Genesis 核心概览
Genesis 是一个开源、基于 GPU 并行加速的生成式物理引擎,由卡内基梅隆大学联合 20 多所高校与研究机构共同开发。它专为机器人、具身 AI 和物理 AI 应用设计,旨在打造一个高度逼真、完全透明、用户友好的仿真生态系统。
1.1 核心设计目标
- 极致的性能:仿真速度宣称比实时快 430,000 倍,支持数千个环境并行仿真。
- Python化与易用性:完全用 Python 开发并开源,API 设计简洁直观。
- 统一的物理求解框架:整合了刚体、可变形体、流体、软体等多种物理现象的模拟。
- 高质量渲染:提供光栅化与光线追踪两种渲染器,支持照片级真实感渲染。
- 生成式数据引擎:能够根据自然语言描述自动生成仿真场景、任务与数据。
1.2 核心特性解析
性能与并行化
- 大规模并行仿真:通过 n_envs 参数轻松创建数千个并行环境,极大加速强化学习训练。
- 多后端支持:支持 CPU、CUDA、Vulkan 和 Metal 后端,实现跨平台高性能计算。
物理仿真能力
- 多种材料与现象:可模拟刚体、软体、流体、可变形体等。
- 精确的接触力学:提供物理精确且可微分的触觉传感器模拟。
- 统一求解器:内置 MPM(物质点法)、FEM(有限元)、PBD(位置基动力学)等先进求解器。
渲染与可视化
- 交互式查看器:实时 3D 可视化,支持视频录制与截图。
- 多模态输出:可渲染 RGB 图像、深度图、分割掩码和表面法线图。
- 光线追踪:集成 LuisaRender,实现照片级真实感渲染。
生成式 AI 集成
- 自然语言驱动:用户可通过文本提示生成仿真场景、任务、奖励函数等。
- 自动化数据生成:为机器人学习自动生成大规模、多样化的训练数据。
2、 安装与配置指南
2.1 快速安装 (Linux 推荐)
2.2 验证安装
3、 核心概念及基本使用
3.1 基本组件
- 场景 (Scene):所有仿真元素(物体、机器人、传感器)的容器。管理物理引擎和可视化器。
- 实体 (Entity):代表仿真中的物体或机器人。通过 Morph(描述几何形状与姿态)添加到场景。
- Morph 类型:基本形状:Plane(), Box(), Sphere(), Cylinder()。文件加载:MJCF(), URDF(), Mesh() 支持多种格式。地形:Terrain() 支持高度图生成复杂地形
- 传感器与渲染:相机:支持 RGB、深度、分割、法线图的多模态输出。录制功能:可轻松录制仿真视频。
3.2 快速开始
以下是一个基础仿真示例,展示如何加载一个 Franka 机械臂并让其自由落体:
4、进阶应用
4.1 机器人控制与运动规划
Genesis 集成了逆向运动学 (IK) 和运动规划功能:
4.2 大规模并行训练
通过简单设置即可实现万级环境并行:
5、学习资源与社区
6.5 Gazebo
更详细见【6.5-Gazebo.md】(详见 files/foundations/6.5-Gazebo.md)
1、 Gazebo 核心概览
Gazebo 是一个开源、功能强大的 3D 机器人仿真环境,由开源机器人基金会(OSRF)开发维护。它提供了一个逼真的物理引擎、传感器模拟和3D可视化环境,广泛应用于机器人研究、教育和工业开发。
1.1 核心设计理念
- 高保真物理仿真:集成 ODE、Bullet 等物理引擎,提供精确的动力学模拟
- 丰富的传感器模型:支持激光雷达、摄像头、IMU、力传感器等多种传感器
- ROS 深度集成:与 ROS/ROS2 生态系统无缝对接
- 开放生态系统:开源社区驱动,拥有大量预建模型和插件
1.2 核心特性深度解析
物理仿真能力
- 多物理引擎支持:默认集成 ODE,支持 Bullet、SimBody、DART
- 精确的接触力学:模拟摩擦、碰撞、关节约束等复杂物理现象
- 刚体动力学:支持复杂机器人系统的运动学和动力学仿真
- 环境交互:模拟机器人与各种环境的真实交互
传感器仿真系统
- 视觉传感器:单目/立体相机、深度相机、RGB-D 传感器
- 距离传感器:2D/3D 激光雷达、声纳、红外测距
- 惯性传感器:IMU、陀螺仪、加速度计
- 力/力矩传感器:六维力传感器、触觉传感器
渲染与可视化
- 高质量图形渲染:基于 OGRE 引擎的逼真 3D 渲染
- 实时可视化:支持模型、传感器数据、调试信息的实时显示
- 光照与材质:动态光照、阴影、材质纹理支持
- GUI 界面:直观的图形用户界面,便于场景构建和调试
插件系统
- 世界插件:控制仿真世界的全局行为
- 模型插件:为特定模型添加自定义行为
- 传感器插件:扩展传感器功能和数据处理
- 系统插件:与外部系统集成的接口
2、 安装与配置指南
2.1 Ubuntu 系统安装(推荐)
2.2 验证安装
2.3 Docker 部署
3、 核心概念及基本使用
3.1 核心概念解析
SDF 格式
- 世界文件 (.world):定义整个仿真环境
- 模型文件 (.sdf):定义机器人或物体模型
- 配置文件:模型配置和参数设置
模型组件
- 链接 (Link):刚体部件,具有质量、惯性等物理属性
- 关节 (Joint):连接链接,定义运动约束
- 碰撞几何:用于物理碰撞检测的形状
- 视觉几何:用于渲染显示的形状
插件系统
传感器配置
3.2 快速开始
启动仿真环境
模型加载与操作
- 添加模型:通过 GUI 界面或命令行添加预建模型
- 自定义模型:使用 SDF(Simulation Description Format)定义新模型
- 模型控制:通过 GUI 或程序接口控制模型行为
基础世界文件示例
4、ROS 集成
4.1 Gazebo ROS 包
4.2 启动文件配置
4.3 控制接口
5、进阶应用场景
5.1 移动机器人导航
- SLAM 仿真:测试建图和定位算法
- 路径规划:验证导航堆栈性能
- 传感器融合:多传感器数据融合测试
5.2 机械臂操作
- 运动规划:测试逆运动学和轨迹规划
- 抓取任务:验证抓取策略和力控制
- 装配任务:模拟工业装配场景
5.3 多机器人系统
- 协同任务:多个机器人协同工作
- 通信仿真:模拟机器人间通信
- 群体行为:研究群体机器人行为
5.4 自动驾驶仿真
- 交通场景:模拟复杂交通环境
- 传感器套件:激光雷达、相机、雷达仿真
- 行为预测:测试感知和决策算法
6、 开发工具与工作流
6.1 模型构建工具
- Blender 插件:3D 模型导入和优化
- MeshLab:网格处理和修复
- SolidWorks/URDF 导出:从 CAD 软件导出机器人模型
6.2 调试与可视化
6.3 性能优化
- 模型简化:优化网格复杂度
- LOD 系统:根据距离调整细节层次
- 物理参数调优:平衡精度和性能
7、 学习资源与社区
xml
<!-- 模型插件示例 -->
<model name="my_robot">
<plugin name="controller" filename="libmy controller.so"
<parameter>value</parameter>
</plugin>
</model>
xml
<?xml version="1.0" ?>
<sdf version="1.6">
<world name="default">
<!-- 物理引擎设置 -->
<physics type="ode">
<max_step_size>0.001</max_step_size>
<real_time_factor>1.0</real_time_factor>
</physics>
<!-- 光照 -->
<light type="directional" name="sun">
<pose>0 0 10 0 0 0</pose>
</light>
<!-- 地面 -->
<model name="ground_plane">
<static>true</static>
<link name="link">
<collision name="collision">
<geometry><plane><normal>0 0 1</normal></plane></geometry>
</collision>
<visual name="visual">
<geometry><plane><normal>0 0 1</normal></plane></geometry>
</visual>
</link>
</model>
</world>
</sdf>
7. 开源实物(Real Robots & Tooling)
贡献者:@owner
—————————————————————————————————————————————————————————————————————————————————————————
7.1 LeRobot 简介
LeRobot 是 Hugging Face 于 2024 年 5 月发布的开源机器人学习框架,目标是降低 AI 机器人开发门槛。
GitHub: huggingface/lerobot ⭐ 19,000+ (截至 2025 年 10 月)
官方页面: huggingface.co/lerobot
核心特性: 预训练模型、数据集、硬件支持、Sim2Real
—————————————————————————————————————————————————————————————————————————————————————————
7.2 快速开始
环境安装
数据集可视化
训练与评估
7.3 硬件平台与数据集
支持的硬件
常用数据集
更多: LeRobot Datasets (160+)
7.4 学习资源
官方资源
中文教程
知乎搜索: "LeRobot" 或 "具身智能"
社区
Discord: Hugging Face Discord #lerobot
核心论文
ACT: arXiv:2304.13705 - 双臂精细操作
Diffusion Policy: arXiv:2303.04137 - 复杂轨迹
TDMPC: arXiv:2203.04955 - 实时控制

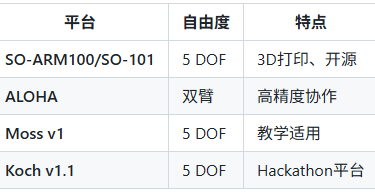


—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
8. 人物(people)
贡献者:@Mumu
维护者:@Mumu
规模:120 人
关键词:Embodied AI / Robot Manipulation / Humanoid / Whole-Body Control / VLA
本名录聚焦 具身智能(Embodied AI) 领域中,对机器人操作(Manipulation) 与 人形 / 全身控制(Humanoid / WBC)具有长期、系统性影响力的学术界与产业界核心人物
—————————————————————————————————————————————————————————————————————————————————————————
🔗 链接类型说明
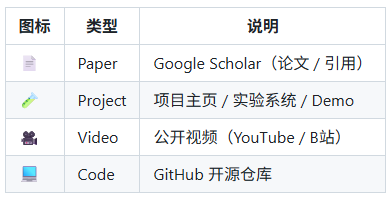
—————————————————————————————————————————————————————————————————————————————————————————
🏫 Berkeley / BAIR(操作 & 机器人学习)
⬆️ 上面 6–12 项 格式与前述完全一致,为避免 README 过长,此处省略重复链接展示
(你可以用脚本或手动补齐)
—————————————————————————————————————————————————————————————————————————————————————————
🏫 Stanford(操作 & 机器人学习)
—————————————————————————————————————————————————————————————————————————————————————————
🏫 CMU Robotics Institute(操作 & 人机协作)
—————————————————————————————————————————————————————————————————————————————————————————
🏫 MIT(控制 / 操作 / 机器人学习)
—————————————————————————————————————————————————————————————————————————————————————————
🤖 Google DeepMind / Google Robotics
—————————————————————————————————————————————————————————————————————————————————————————
🧠 FAIR / Meta AI
—————————————————————————————————————————————————————————————————————————————————————————
🎓 其他北美高校
—————————————————————————————————————————————————————————————————————————————————————————
🌍 欧洲 / 英国
—————————————————————————————————————————————————————————————————————————————————————————
🏭 国际产业界(人形 / 操作)
—————————————————————————————————————————————————————————————————————————————————————————
🇨🇳 国内高校 / 研究所
—————————————————————————————————————————————————————————————————————————————————————————
🇨🇳 国内产业界(人形 / 操作)
—————————————————————————————————————————————————————————————————————————————————————————
📌 维护说明
本名录为 长期维护型资源
推荐做法:
README 保留 检索入口
子页面 / Wiki 存放 精确代表作
欢迎 PR / Issue 补充或修订人物信息
—————————————————————————————————————————————————————————————————————————————————————————
9. 具身公司图谱(Landscape)
贡献者:@bob
目录
9.1 硬件整机(人形/四足/移动+操作)
9.2 关键部件(力控手、末端执行器、传感器)
9.3 算法与平台(VLA/策略/仿真/评测工具)
9.4 数据与服务(采集/标注/云端训练)
—————————————————————————————————————————————————————————————————————————————————————————
9.1 硬件整机(人形 / 四足 / 移动+操作)
中国大陆 / 港澳
1. 智元机器人 AgiBot(中国·上海)
背景:2023 年成立,发布 G1/GX 系列与「AgiBot World」等配套生态。规模:200–500(估)
主营:通用具身机器人(人形/移动交互)、具身数据与仿真平台
2. 浙江人形机器人创新中心(中国·宁波)
背景:2023-12 注册,产学研平台,发布「领航者1号」原型。规模:100–300(估)
主营:人形机器人整机与感知/控制/本体关键技术研发
3. 银河通用 GALBOT(中国·北京)
背景:专注通用机器人与人形方向的创业公司(公开资料较少)。规模:50–200(估)
主营:通用机器人整机与系统应用
官网:galbot.com
4. 优必选 UBTECH(中国·深圳)
背景:2012 年成立;2023-12 于港交所上市(9880.HK)。规模:1000+
主营:人形机器人(Walker 系列)、商服/教育/养老等服务机器人
官网:ubtrobot.com
5. 宇树机器人 Unitree(中国·杭州)
背景:四足机器人代表企业。规模:200–500(估)
主营:四足平台(Go 系列)、人形 H1 等
官网:unitree.com
6. 傅利叶智能 Fourier Intelligence(中国·上海/新加坡)
背景:康复机器人起家,近年发布人形 GR-1。规模:500–1000(估)
主营:人形机器人 GR-1、康复机器人 RehabHub
官网:fftai.com
7. Flexiv 非夕(中国·上海 / 美国)
背景:2016 年创立,力控+视觉的自适应协作臂。规模:200–500(估)
主营:Rizon 协作臂、力控应用单元
官网:flexiv.com
8. 节卡机器人 JAKA(中国·上海)
背景:协作机器人厂商。规模:500–1000(估)
主营:JAKA Zu/All 系列协作臂、移动+操作单元
官网:jaka.com
9. 珞石机器人 Rokae(中国·北京)
背景:工业/协作机器人厂商。规模:500–1000(估)
主营:XMate/CR/AR 系列协作与工业臂
官网:rokae.com
10. 越疆 DOBOT(中国·深圳)
背景:桌面/教育到工业协作臂全栈产品。规模:500–1000(估)
主营:CR/CRS/MG 等协作臂与教育平台
官网:dobot.cc
11. 高仙机器人 Gaussian(中国·上海)
背景:商用清洁机器人龙头。规模:500–1000(估)
主营:室内外清洁机器人、设施运维解决方案
12. 普渡机器人 Pudu Robotics(中国·深圳)
背景:商用配送/清洁机器人,全球出货过万台级。规模:1000+(估)
主营:餐饮配送/酒店/清洁/工业配送
13. 擎朗智能 KEENON(中国·上海)
背景:2010 年成立,商服机器人出海较早。规模:1000+(估)
主营:送餐/酒店/清洁/重载系列
官网:keenon.com
14. 极智嘉 Geek+(中国·北京)
背景:AMR(货到人/搬运/拣选)全球化布局。规模:1000+(估)
主营:仓储 AMR 系列与调度软件
官网:geekplus.com
15. 海柔创新 HAI Robotics(中国·深圳)
背景:料箱到人(CTU)赛道开创者之一。规模:1000+(估)
主营:料箱到人系统、仓储自动化
16. 快仓 Quicktron(中国·上海)
背景:2014 年成立,AMR 头部企业。规模:500–1000
主营:仓储/制造 AMR 全系与系统
17. 海康机器人 HIKROBOT(中国·杭州)
背景:工业视觉+AMR 业务。规模:1000+(估)
主营:移动机器人、视觉/读码器与产线解决方案
18. Syrius Robotics 仙途智能(中国·北京/新加坡/日本)
背景:2018 年成立,RaaS 与 3PL 场景落地较多。规模:200–500(估)
主营:拣选/搬运 AMR、FlexGalaxy.AI 调度与 RaaS
19. Multiway Robotics 未来机器人(中国·深圳)
背景:AMR 及柔性工厂内物流解决方案。规模:200–500(估)
主营:托盘/潜伏举升/搬运 AMR 与系统集成
20. YOUiBot 优艾智合(中国·深圳)
背景:2015 年成立,半导体/电力/巡检 AMR。规模:200–500(估)
主营:室内外 AMR 与行业解决方案
官网:youibot.com
21. Mech-Mind 梅卡曼德(中国·北京)
背景:AI+3D 视觉与机器人系统集成,支持抓取/拆码垛/拣选。规模:500–1000(估)
主营:3D 相机 + Mech-Vision/Viz/Centre 软件与整线方案
注:后续可按照提交模板将更多同赛道代表企业分别拆分为 /landscape/<company>.md,并逐步补齐到 ≥30 家。
海外(北美 / 欧洲 等)
22. Boston Dynamics(美国)
背景:1992 年起步,现属现代汽车集团。规模:500–1000
主营:四足 Spot,物流臂 Stretch,研发人形 Atlas
23. Agility Robotics(美国)
背景:2015 年成立;人形 Digit 量产推进。规模:200–500
主营:人形搬运/拣选/物流场景
24. Figure AI(美国)
背景:人形 Figure 01;多家头部科技/零售合作。规模:200–500
主营:通用人形机器人与具身智能
官网:figure.ai
25. 1X(美国/挪威)
背景:2014 年创立(前身 Halodi),人形/移动人形。规模:200–500
主营:双足/轮足人形、远程操作与守护场景
官网:1x.tech
26. Apptronik(美国)
背景:源自德州大学实验室,通用人形 Apollo。规模:100–300
主营:人形在制造/物流中的部署
27. Sanctuary AI(加拿大)
背景:通用人形 Phoenix;认知与远程操作结合。规模:100–300
主营:人形服务/工业任务代理
官网:sanctuary.ai
28. Tesla Optimus(美国)
背景:特斯拉的人形项目「Optimus」。规模:N/A(集团内)
主营:制造场景的人形装配/搬运实验
页面:tesla.com/AI(Optimus 板块)
29. PAL Robotics(西班牙)
背景:2004 年成立,人形/双臂/移动服务机器人老牌公司。规模:100–300
主营:TIAGO/ARI 等服务与研究平台
30. ANYbotics(瑞士)
背景:苏黎世联邦理工孵化,四足 ANYmal。规模:100–300
主营:油气/化工/电力巡检
31. Ghost Robotics(美国)
背景:四足平台厂商。规模:50–200
主营:安防/勘察四足平台
32. NEURA Robotics(德国)
背景:2019 年成立,协作与人形 4NE1;近年获大额融资。规模:200–500
主营:认知机器人、协作臂、人形平台
33. Agile Robots(德国/中国)
背景:慕尼黑总部,AI+机器人自动化。规模:500–1000(估)
主营:协作臂、移动/视觉检测一体化解决方案
34. ABB Robotics(瑞士)
背景:全球工业机器人巨头之一。规模:7000+(机器人业务)
主营:工业/协作机器人与 AMR、软件与系统集成
35. KUKA(德国)
背景:世界领先的工业机器人与系统集成商。规模:>10,000(集团)
主营:工业/协作机器人、移动底盘与整线解决方案
官网:kuka.com
—————————————————————————————————————————————————————————————————————————————————————————
—————————————————————————————————————————————————————————————————————————————————————————
10. Ask Me Anything(提 Issue 问我任何)
贡献者:全体维护者
在本仓库 开 Issue 提问(学习/复现/工程落地/选型/合作都可)
使用模板 “AMA 问答”(自动标签:question,AMA)
Issue 模板(.github/ISSUE_TEMPLATE/ama.md)
—————————————————————————————————————————————————————————————————————————————————————————
11. 如何贡献 & 目录约定
贡献者:@owner
PR 规则:一事一 PR;附最小可复现;图片入 assets/;脚本入对应子目录
章节贡献:每章末尾都保留“贡献者:@xxx”,请在你的 PR 中追加自己的 ID
目录结构建议
提交检查清单
有 README/复现步骤/命令
有最小可跑脚本与日志/图
标注数据来源与许可证
在对应章节补上你的「贡献者」ID
License
本仓库采用 MIT(代码)与 CC BY 4.0(文档)双许可;外部素材遵循原许可。
—————————————————————————————————————————————————————————————————————————————————————————
备注
四大主线顺序已符合你最初要求:1 综述 → 2 各方向学习路线 → 6 仿真 → 7 开源实物;同时补充了你追加的三章:3 基础学习、4 各技术基础与经典、5 各技术路线前沿。
章节下方都留有贡献者位;AMA/Issue 模板、Isaac Lab 与 LeRobot 的可跑样板、以及 Diffusion Policy / VLA 路线样板均已内置。
需要的话,我可以把上述子目录与 Issue 模板一并生成到仓库的初始提交版本。
—————————————————————————————————————————————————————————————————————————————————————————
12. 版本与致谢
版本节奏:每周一同步合入;月末发布小版本(Changelog)。
维护团队:Xbotics 社区志愿者 & 合作伙伴。
致谢:感谢所有贡献者的链接推荐、SOP 总结与复现实验。
💡 有想加入的方向?直接开 Issue;也欢迎在 Discussions 里提需求与想法。